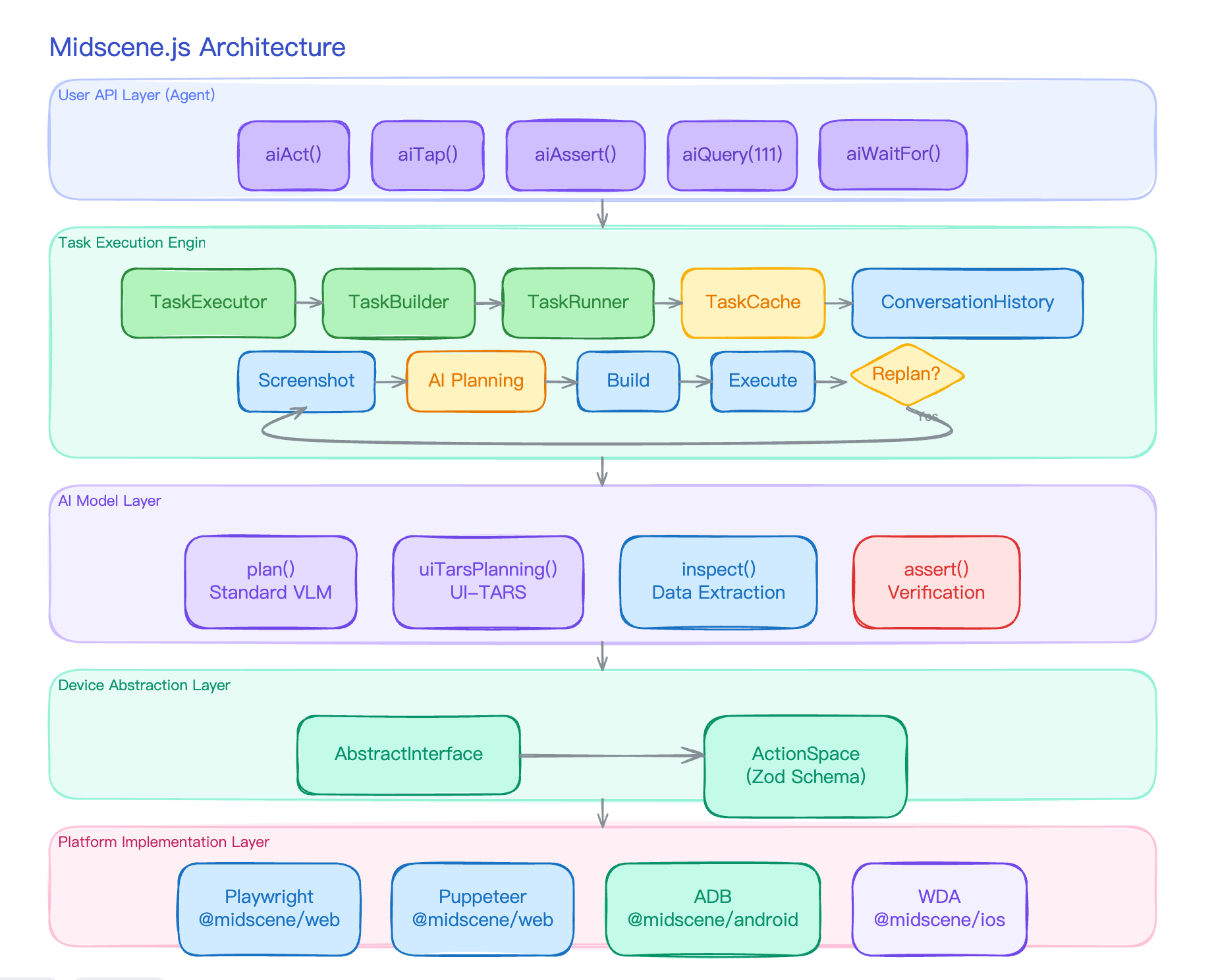
Turning Vibecoding Debt into a Harness (00): Building a Local Harness in Public, on a Real Repo
If you also write real product code with AI, this feeling will be familiar: a feature ships fast, but a few days later you change something else and the earlier thing quietly breaks.
Every release needs a human in the loop — deciding by hand which tests to run, which logs to read, which failures to ignore, and which ones must be fixed. There’s no real confidence underneath it.
I’m building a harness now, not out of engineering perfectionism, but because these pain points have shown up too many times. So I decided to do this in public — a Build in Public series with one theme: standing up a harness inside a real monorepo.