Frontend Monorepo Practices at ByteDance
Invited to speak at the 11th Top100 Summit. For more details, see the article Year-end Review: How These 100 Tech Innovation Leaders Do Retrospectives
Background
Invited to speak at the 11th Top100 Summit. For more details, see the article Year-end Review: How These 100 Tech Innovation Leaders Do Retrospectives
About This Topic

Slides

- Good morning everyone, I’m Lin Yibing. Today I’ll be sharing on the topic of “Frontend Monorepo Practices at ByteDance.”

- Let me briefly introduce myself. I’m from ByteDance’s Web Infra team, with years of experience in frontend engineering. My focus is on helping frontend engineers better manage and govern their projects.
- Currently, I’m responsible for the design and implementation of our frontend Monorepo solution, with extensive experience in Monorepo practices and governance.

- Today’s talk is divided into five parts:
- First, we’ll analyze the trends in “modern frontend development” and identify the pain points faced by frontend development at ByteDance.
- Second, we’ll briefly introduce Monorepo and explain why it can address our pain points.
- Third, we’ll discuss the challenges we encountered during implementation and our practical solutions.
- Fourth, we’ll share the adoption status of our in-house solution at ByteDance.
- Finally, we’ll summarize the current issues and outline our future plans.
- OK, let’s first look at several trends in modern frontend development.
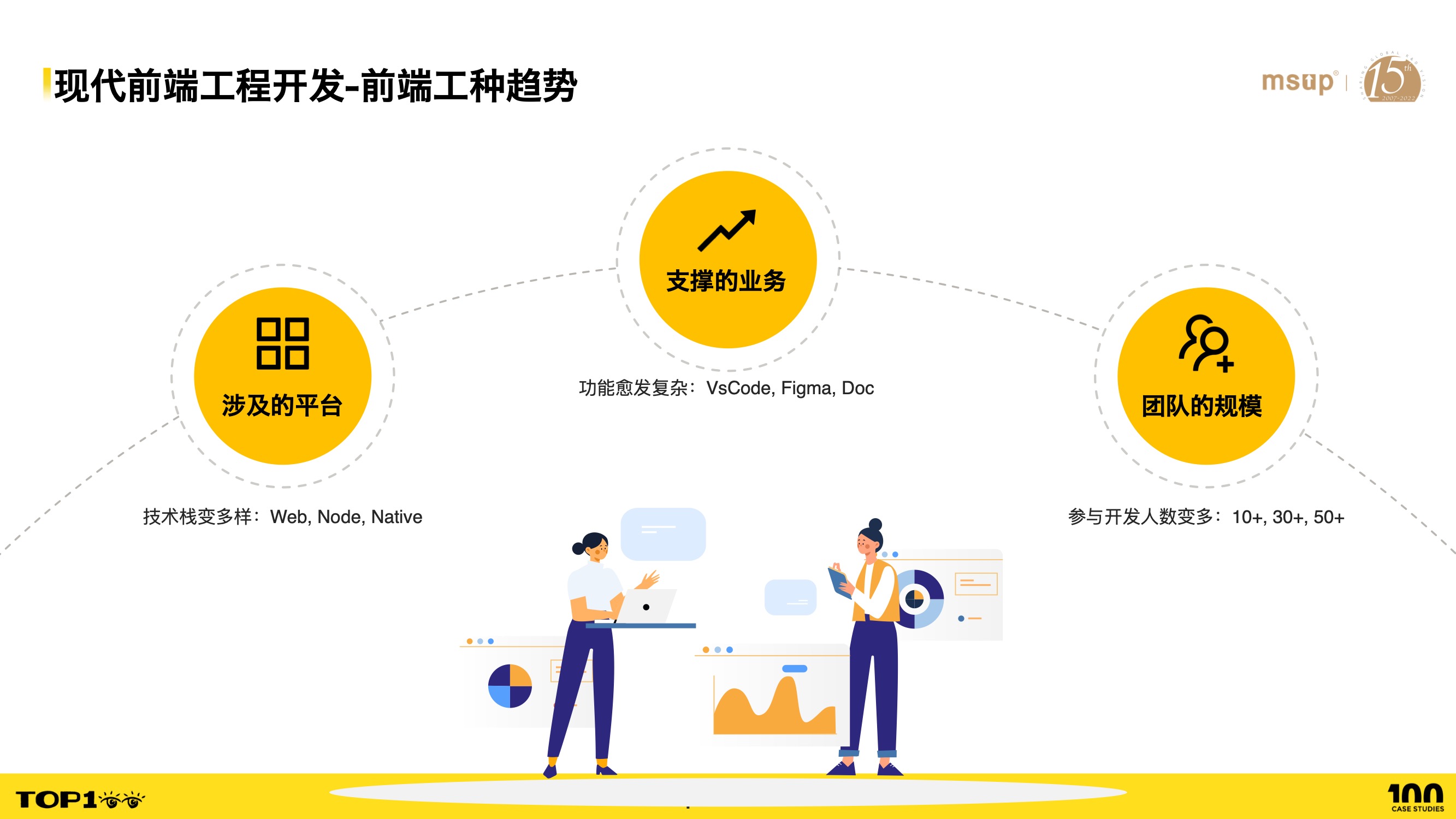
- First, let’s look at the trends in frontend roles:
- The first trend is that the number of platforms keeps growing — Web, Node, native clients, cross-platform, and more.
- The second trend is that the business applications they support are becoming more numerous and complex, especially with the emergence of frontend-heavy interactive applications in recent years, such as design tools like Figma and document tools like Lark.
- The third trend is that, inevitably driven by the first two, frontend team sizes continue to grow.
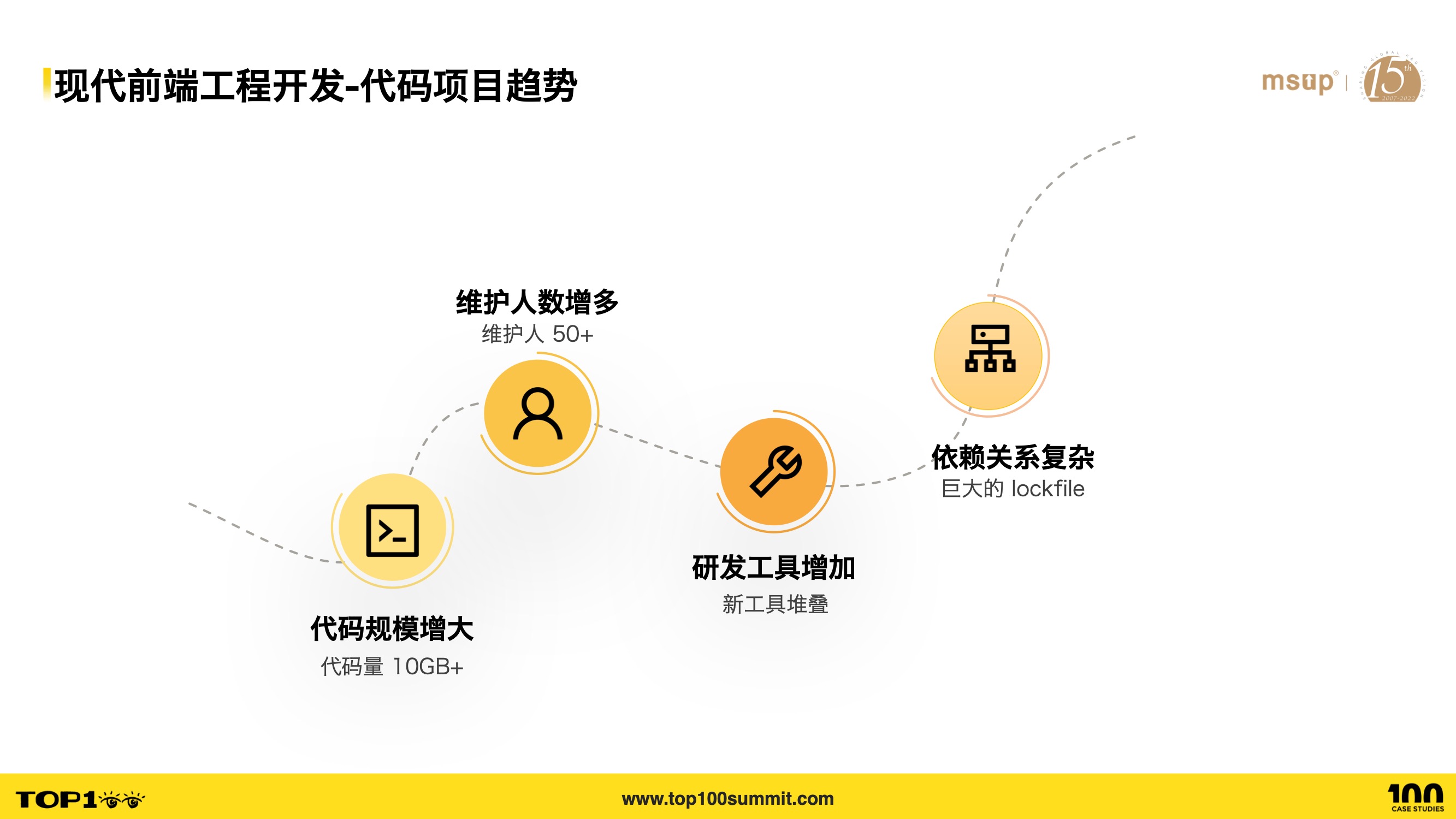
- These three trends have objectively led to four trends in frontend engineering:
- Codebase sizes are increasing — we already have large-scale projects with over 10GB of code internally.
- The number of maintainers is growing — a single project can have anywhere from a dozen to forty or fifty people.
- Development tools are proliferating — new tools keep stacking up on a single project: build tools like webpack, rollup, vite; testing tools like jest, vitest, etc.
- Dependency relationships are becoming complex — the size of lock files after installing dependencies speaks volumes about the complexity.
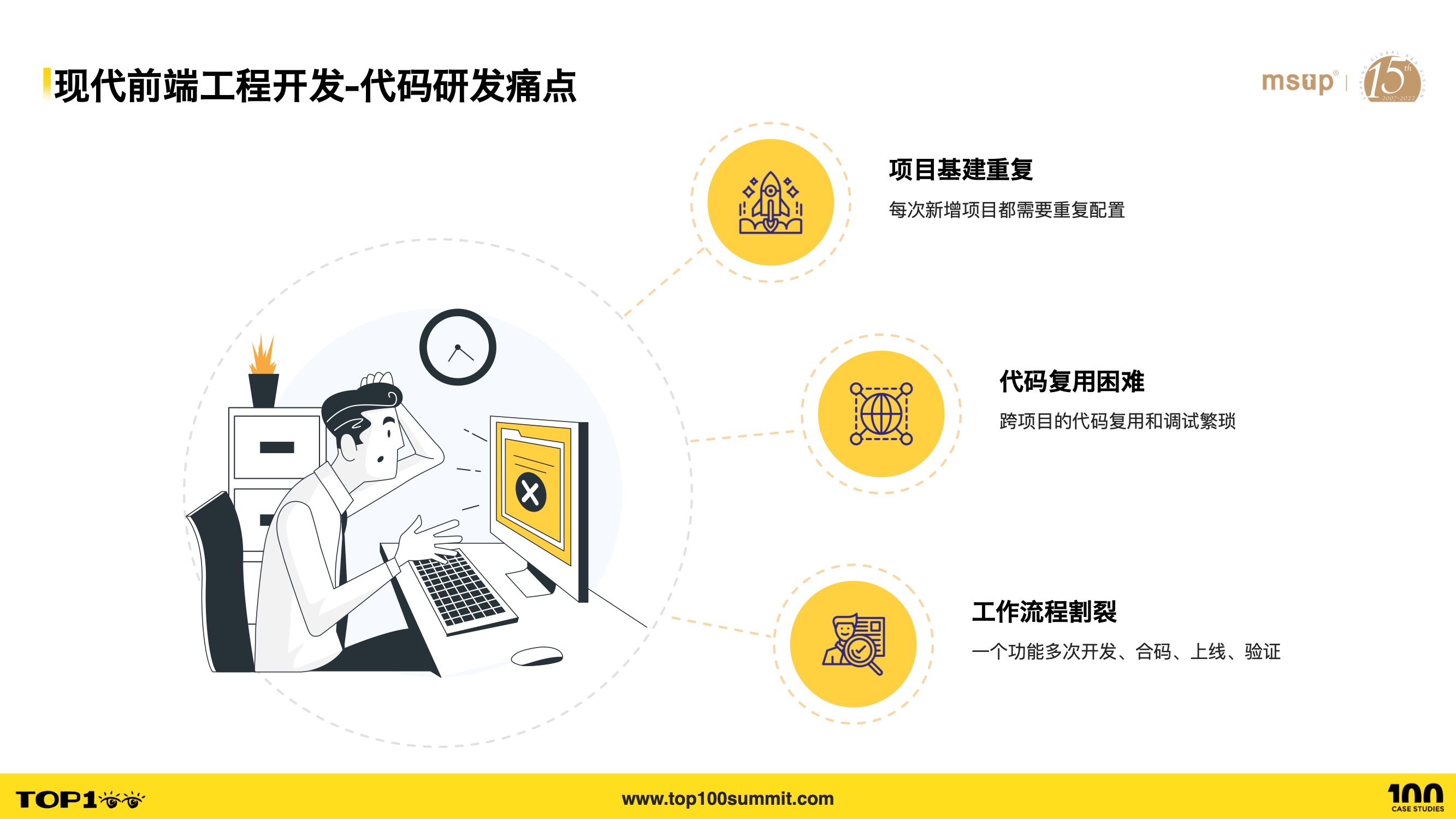
- Given these trends, what pain points does our frontend development face? There are mainly three:
- First, repetitive project infrastructure — every new project requires setting up Git, build platforms, CI/CD configurations, etc. from scratch.
- Second, difficult code reuse — cross-project code reuse and debugging is extremely cumbersome, typically relying on npm packages, which inevitably leads to update adoption issues.
- Third, fragmented workflows — a single feature often spans multiple modules, requiring separate development, code merging, deployment, and verification in each module’s project, which is tedious and disjointed.

- Facing these pain points, how can we better organize our projects to improve maintainability and development efficiency? Our answer is Monorepo!

- Next, let’s briefly introduce Monorepo.
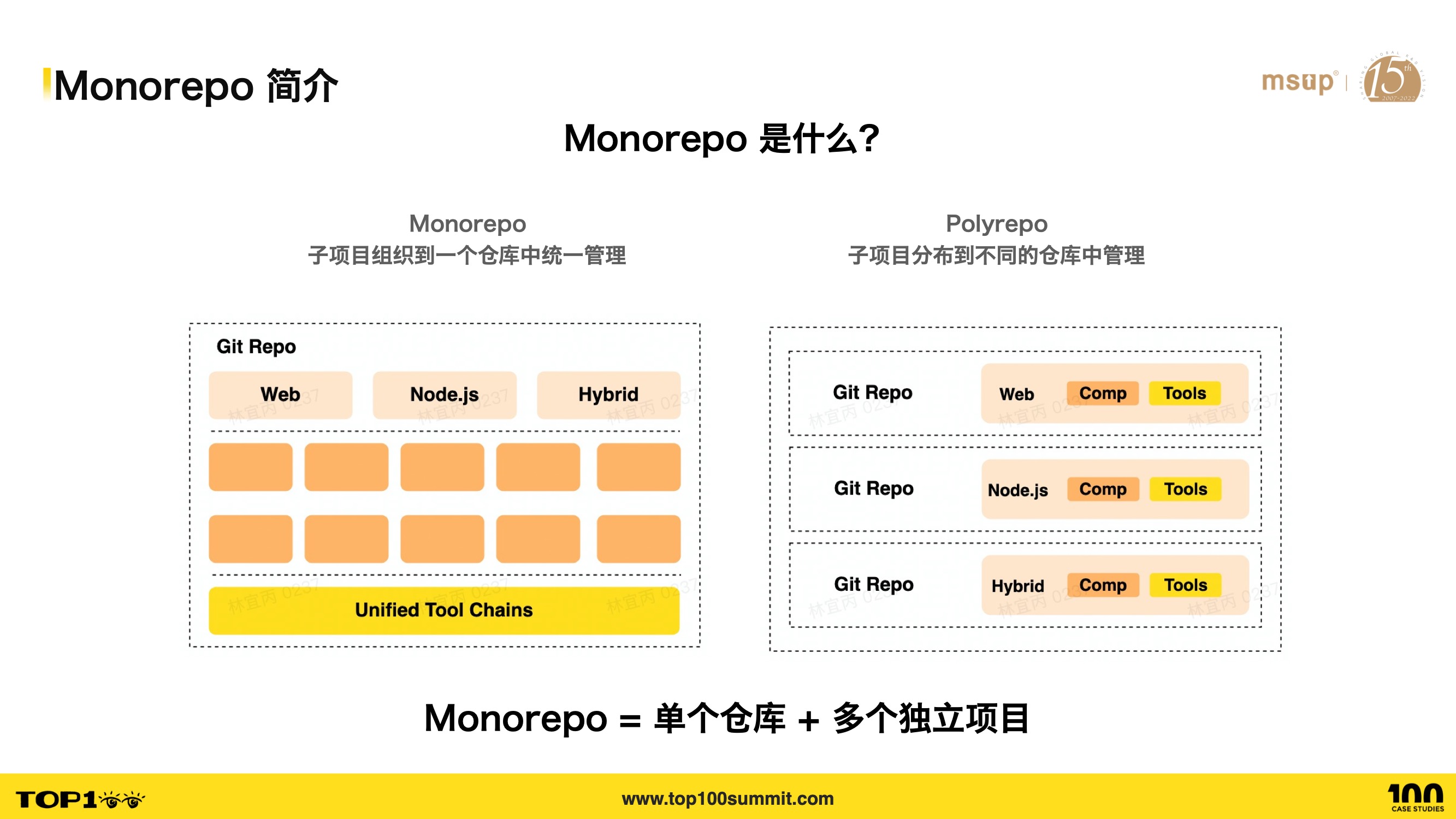
- So what exactly is Monorepo? Monorepo is a source code management pattern where multiple projects are managed within a single repository.
- The opposite of Monorepo is Polyrepo, where each project has its own independent repository.
- It’s important to note that Monorepo isn’t just about putting sub-projects in one repository — managing the relationships between sub-projects is equally important.
- Sub-projects can be of any type — web projects, Node projects, or libraries.
- In short, Monorepo means maintaining multiple different projects in a single repository with well-organized relationships.
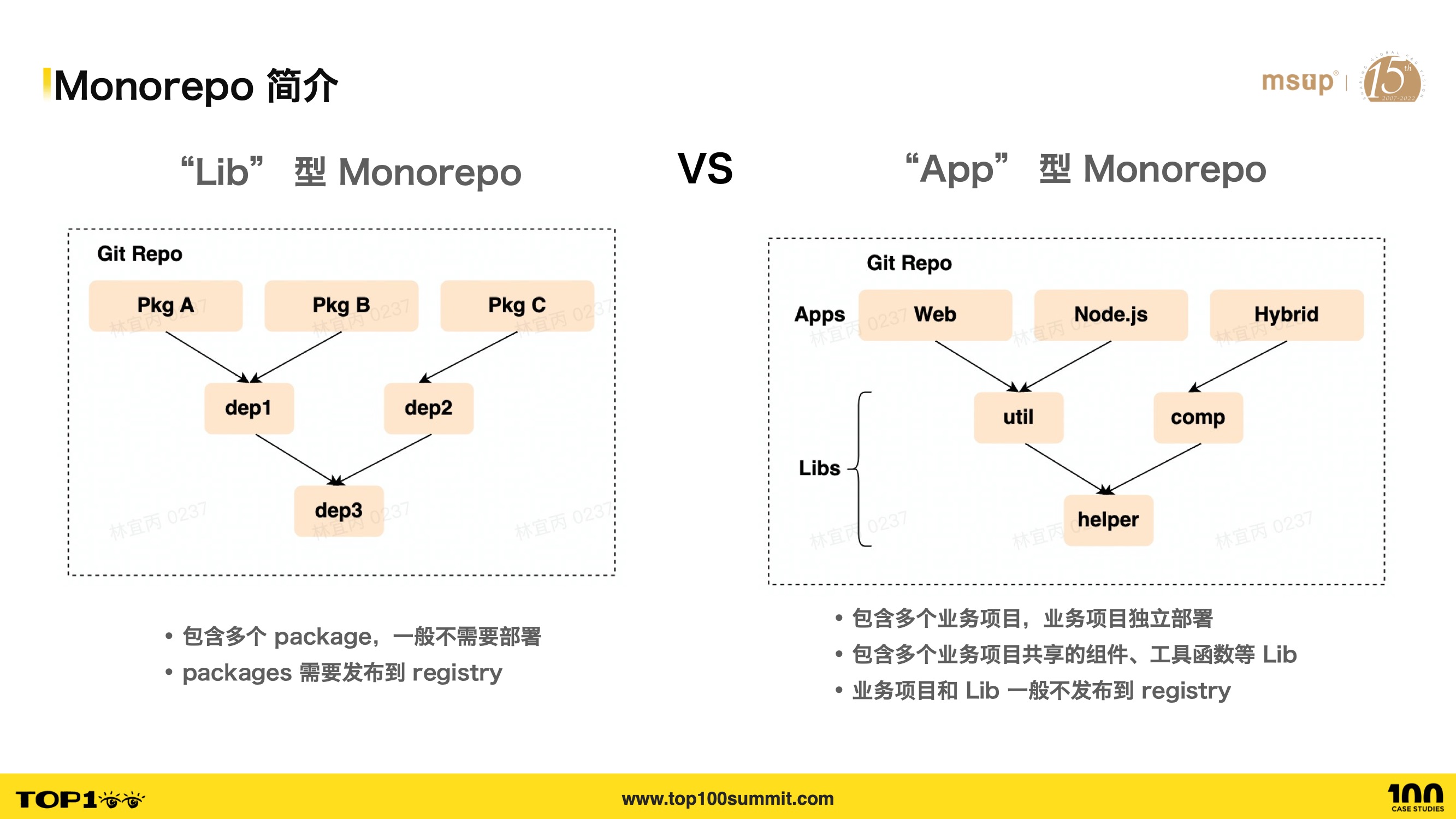
- In the frontend world, you may be more familiar with Library-type Monorepos. Well-known open source projects like React, Vue, and Babel all use Monorepo for source code management. Looking at the diagram on the left, by splitting the entire system into multiple packages, it facilitates abstraction and reuse. These packages typically don’t need to go through online deployment — they just need to be published to the npm registry. I believe most Monorepo projects you encounter at work are of this type, but these aren’t actually the mainstream in commercial companies.
- Besides the Library type, look at the diagram on the right — multiple Apps can also be maintained in a single repository. This is the App-type Monorepo, containing multiple App projects along with shared components, utility functions, etc. App-type projects require a complete deployment process, and the Apps and their dependent libraries generally don’t need to be published to npm registry. This type of project is the mainstream in commercial companies.
- At ByteDance, most projects are App applications. We focus our in-house Monorepo solution on this type, as it covers the most people and applications, delivering the greatest returns. Of course, supporting App-type Monorepo naturally supports Library-type as well.

- So why should we adopt Monorepo? Let’s look at the benefits and how it addresses our pain points.
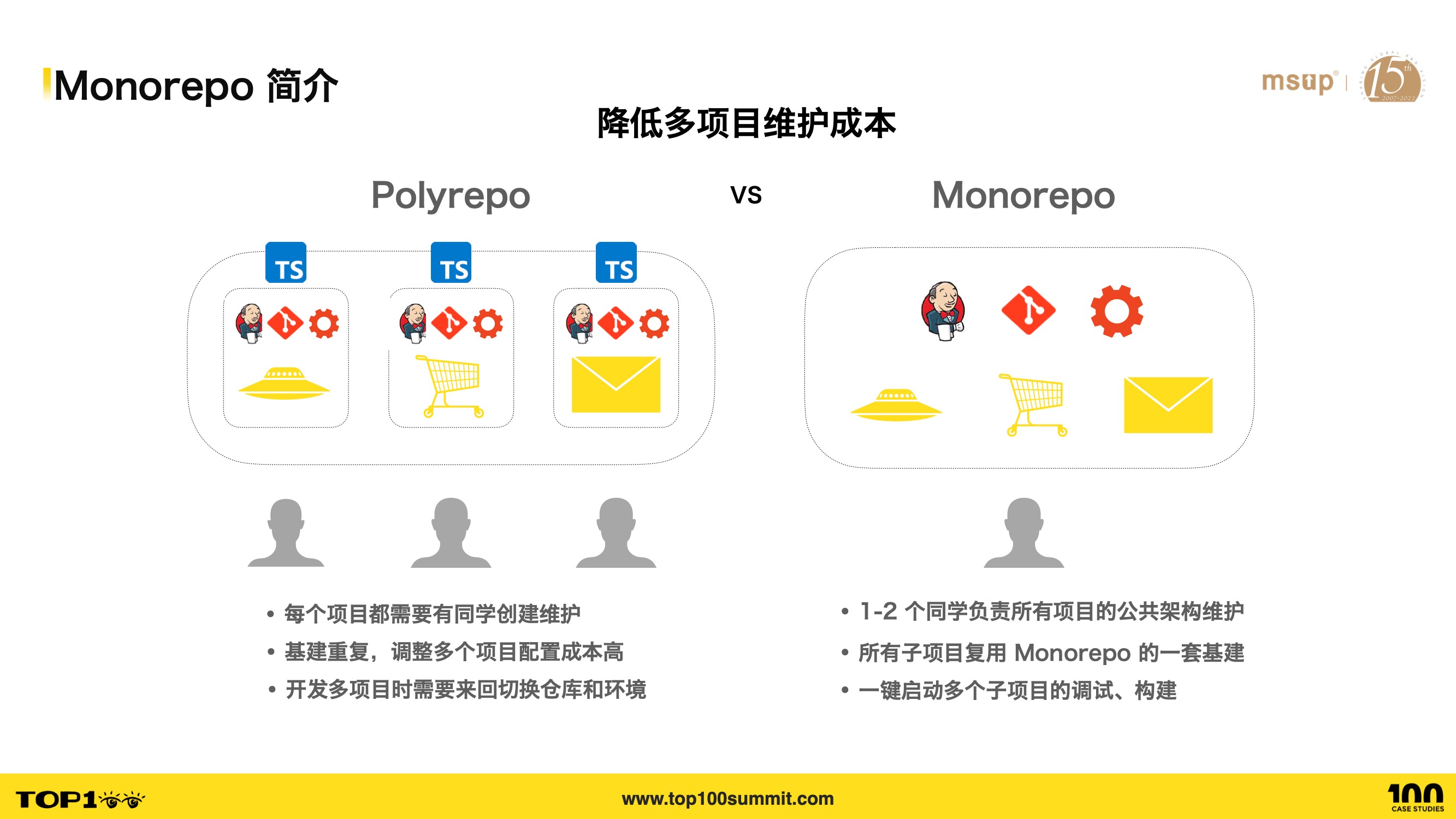
- First, Monorepo can reduce the maintenance cost of multiple projects, addressing the pain point of repetitive infrastructure.
- In Polyrepo, each project needs someone to create and maintain it. When more projects are created, more people or more effort is needed.
- In Monorepo, only a few people need to set up the Monorepo, and all projects — current and future — can be maintained in a unified way within a single repository, reducing multi-project maintenance costs.
- Additionally, in Polyrepo, infrastructure across multiple projects is highly repetitive. When a team has multiple projects, they need to repeatedly create Git repositories, configure CI, lint rules, builds, etc., and each setup needs ongoing maintenance.
- Synchronizing changes across projects is also costly. For example, if you want to add type checking in CI for all projects to improve quality, you’d need to modify each project individually, submit code, and run CI — very expensive. In Monorepo, you only need one set of infrastructure that all sub-projects, including future ones, can plug into.
- In Polyrepo, working on multiple projects may require switching development environments, switching repositories, and linking code. In Monorepo, you can start debugging and building multiple sub-projects with a single command, improving development efficiency.
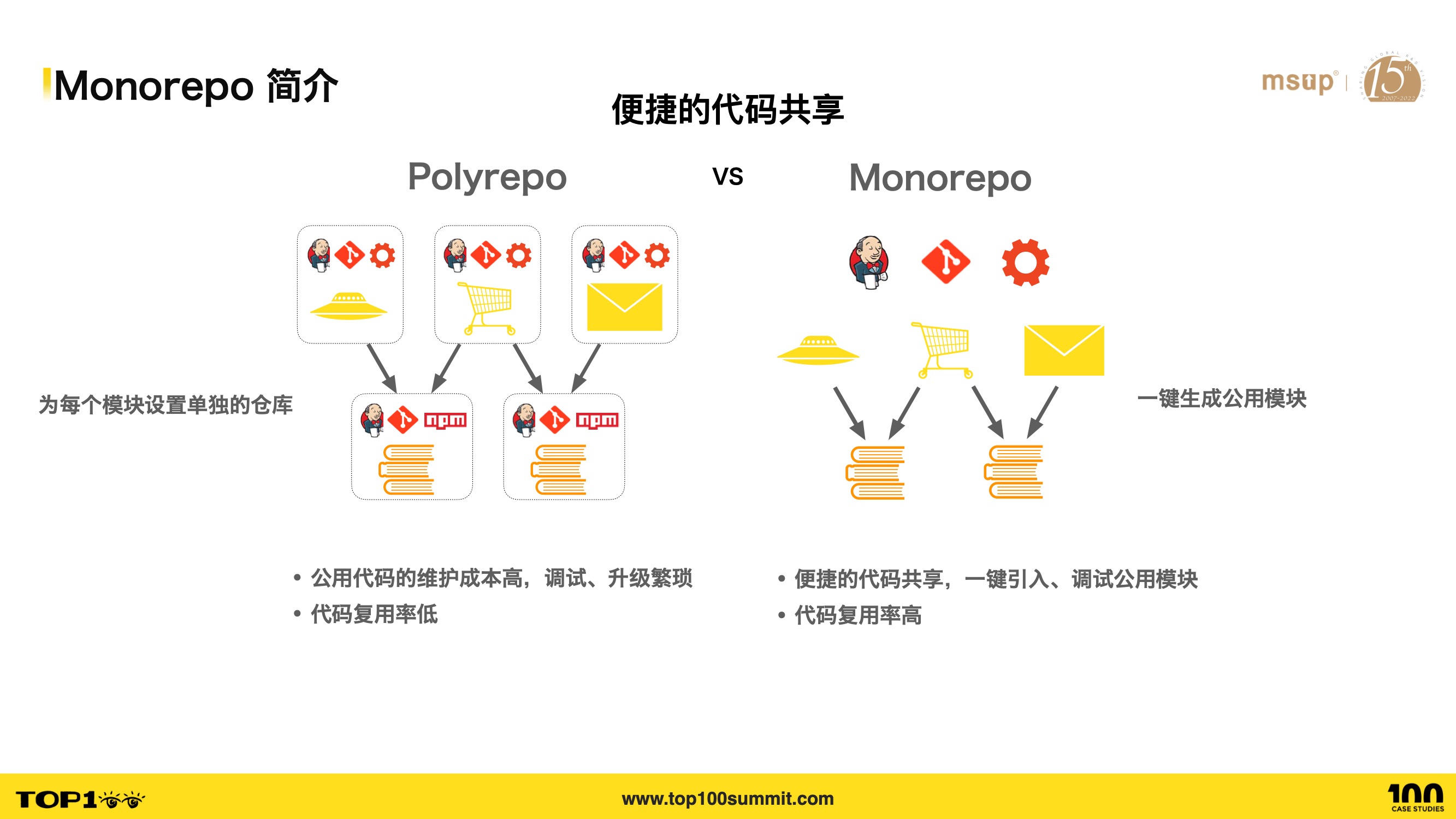
- Second, Monorepo makes code sharing convenient, addressing the pain point of difficult code reuse.
- In Polyrepo, reusing shared code is difficult — you need a separate repository for shared code, and the upgrade and debugging processes are cumbersome and inefficient.
- Debugging is tedious — shared module debugging requires manual linking with the current project. With many shared modules, the linking steps become extremely inefficient.
- Upgrading shared modules is also tedious — you need to manually manage dependency relationships, upgrade bottom-level modules first, publish them, then upgrade top-level modules. If something goes wrong, you have to redo all these steps. Moreover, pushing updates to upstream modules can’t reach consumers in a timely manner.
- In Monorepo, you can create shared modules with one click. Top-level modules can import shared modules for development and debugging with one click. Changes to bottom-level modules are immediately visible to upper layers, without going through linking or npm publishing — they can be debugged locally or published through the deployment platform, eliminating a lot of repetitive work.
- Therefore, while code reuse is difficult in Polyrepo leading to low reuse rates, Monorepo makes code reuse convenient. The low cost of extracting new utility libraries encourages developers to do this kind of extraction work, which in turn improves code reuse rates.
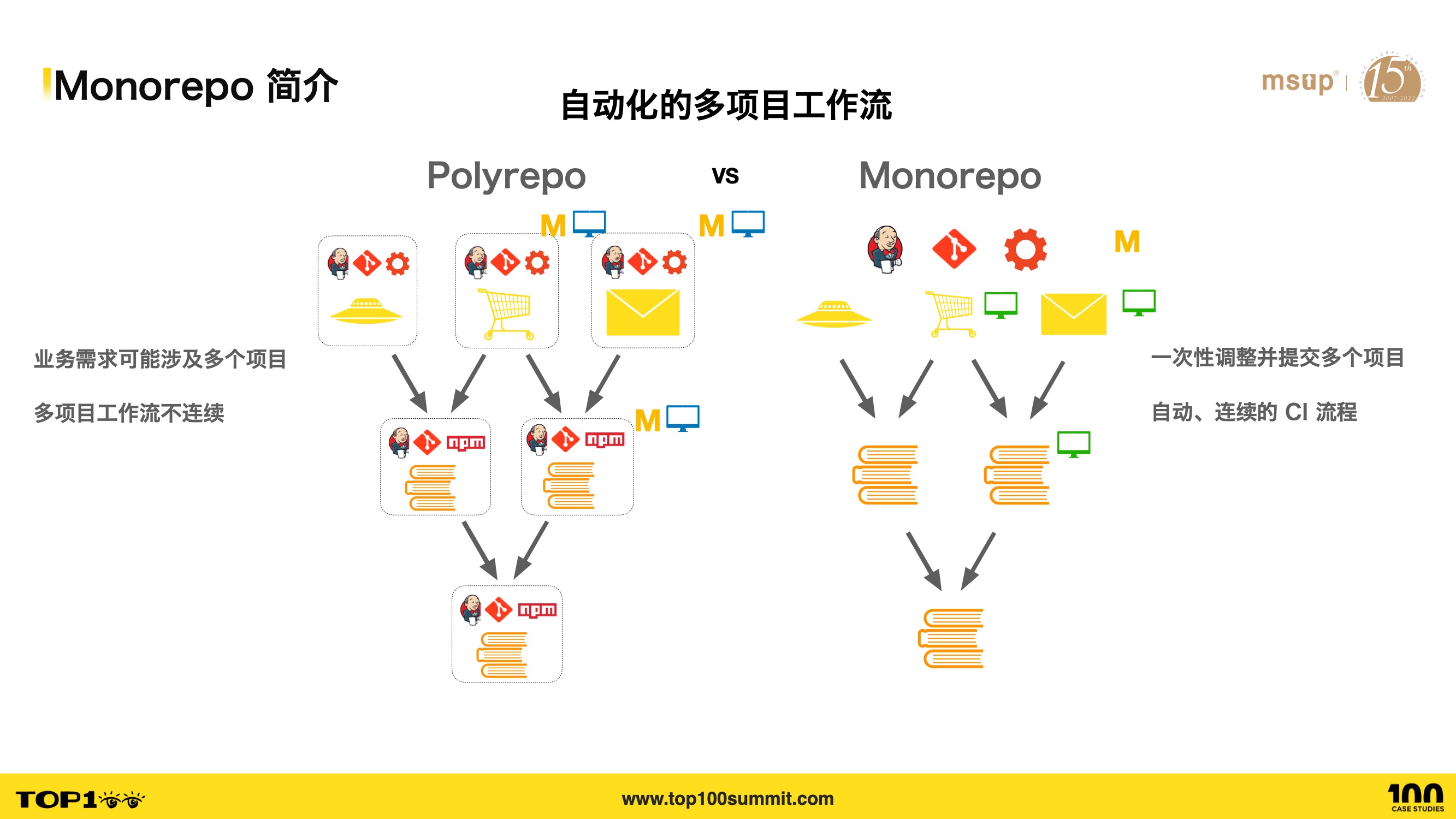
- Third, Monorepo enables automated multi-project workflows, addressing the pain point of fragmented workflows.
- If a business requirement involves multiple projects, in Polyrepo you need to modify multiple projects, submit separate commits for each, run individual CI processes for each, and if there are dependencies between projects, manually upgrade dependency versions. For example, to modify three projects as shown, you’d need to first modify and commit the bottom-level modules, run CI for each, then update dependencies when handling top-level modules, and run CI again. This entire process is very cumbersome and discontinuous.
- In Monorepo, we can directly modify multiple sub-projects, submit with a single commit, and the CI and release processes for multiple sub-projects are also done in one go, automating and streamlining the entire multi-project workflow.
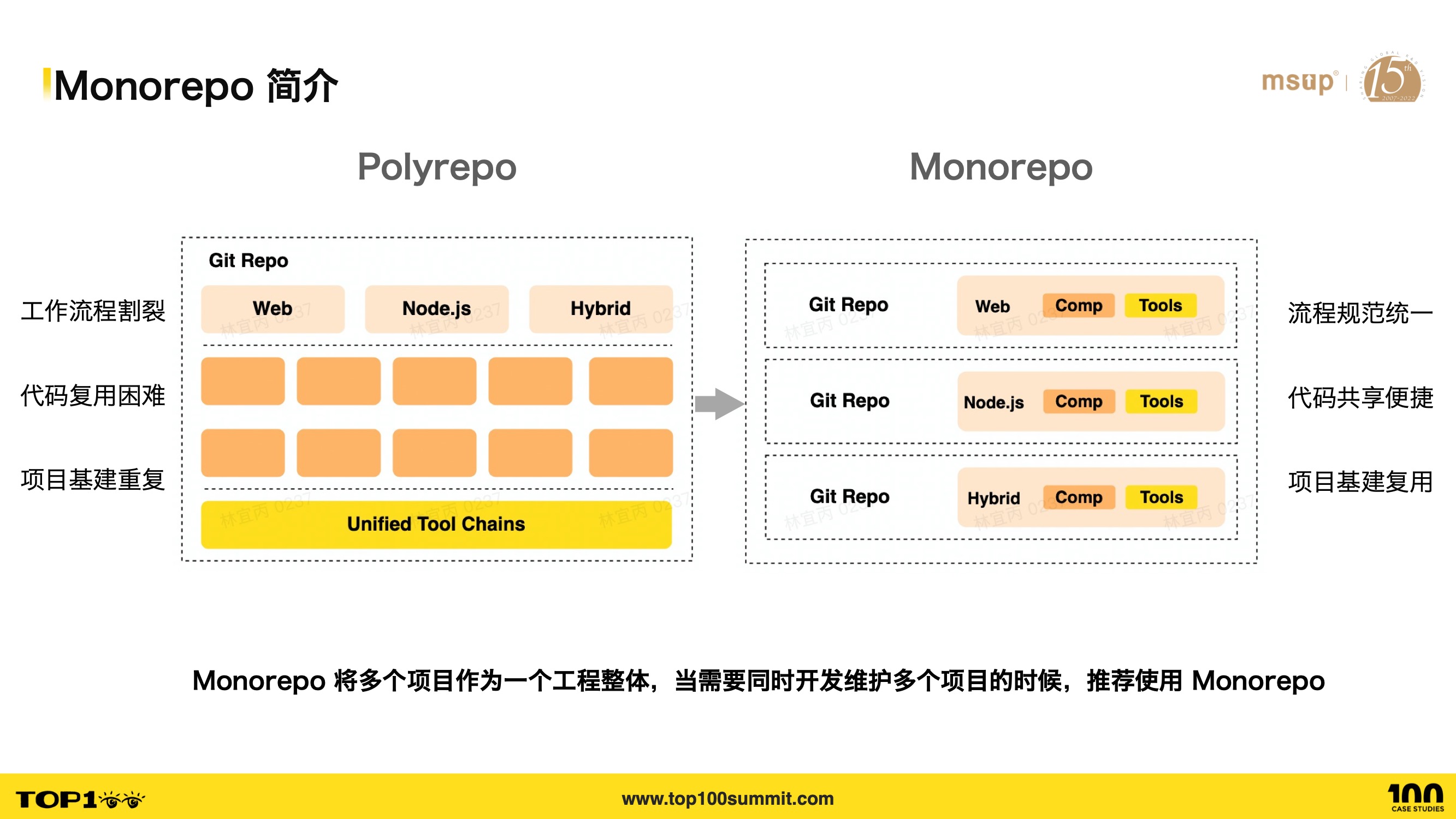
- Let’s do a simple summary: In Polyrepo mode, each project has its own address and repository, which leads to difficult code sharing, repetitive infrastructure, and fragmented workflows.
- In Monorepo, we can unify the workflows of multiple projects — for example, unified CI processes, code reviews, etc. Code sharing is also convenient — we can extract shared components or utility functions to be reused across projects, and infrastructure can be shared as well.
- In many cases, a team’s or business unit’s projects are not completely isolated but interconnected. Monorepo conveniently organizes these projects together for maintenance. When a team has multi-project needs, Monorepo is recommended.
- Of course, Monorepo is not a silver bullet. Polyrepo works for most scenarios too. We chose Monorepo based on our specific pain points and trade-offs. While Monorepo effectively solves our pain points, it also brings additional costs. In the next section, I’ll focus on the problems we encountered after adopting Monorepo and our practical solutions.

- Next, let’s look at the problems we encountered after introducing the Monorepo solution and our practices in solving them.
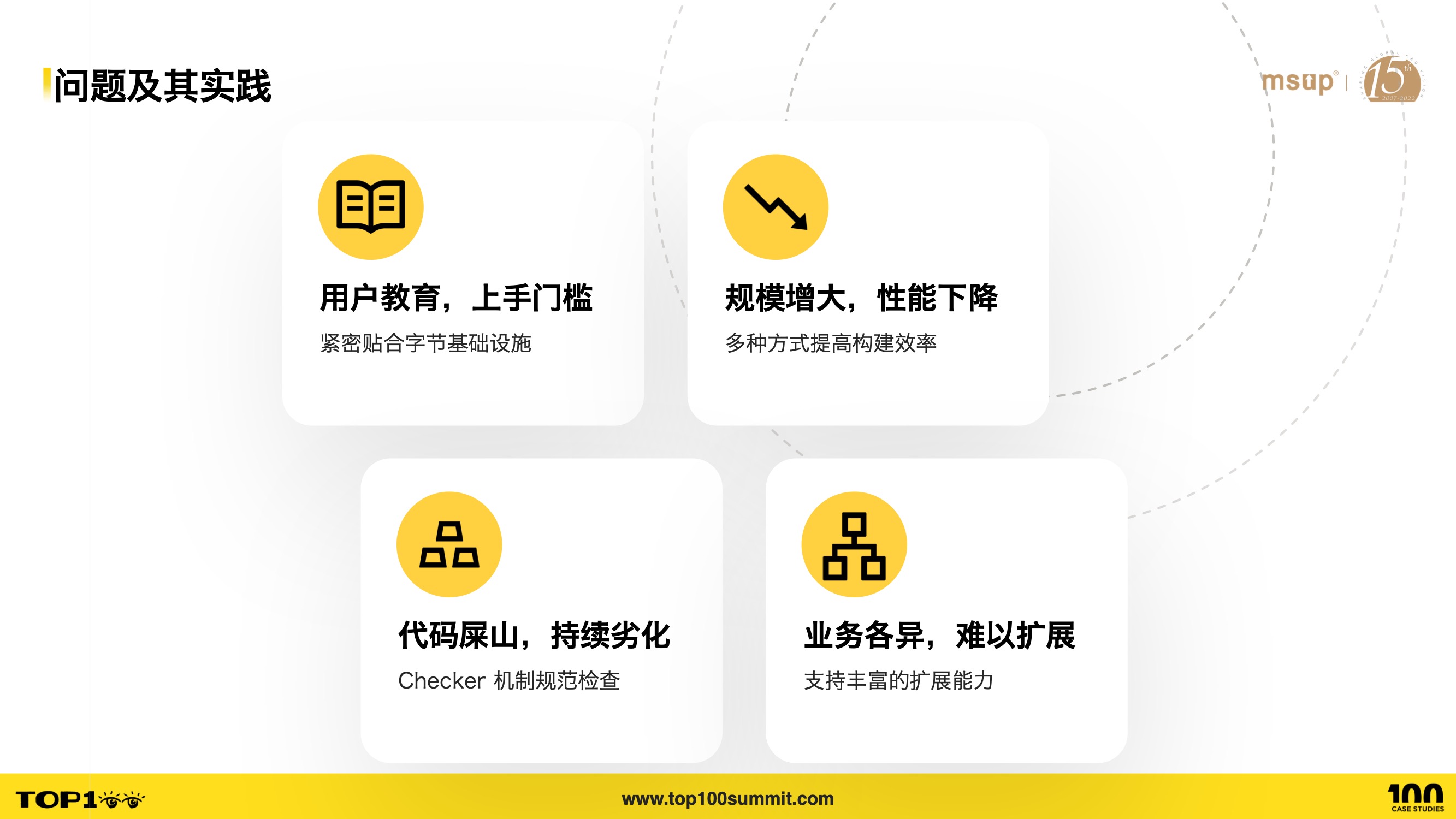
- During the implementation of our in-house solution, we encountered four main categories of problems:
- First, since most users are accustomed to Polyrepo development and some have never used Monorepo before, there are user education and onboarding challenges.
- Second, as the business iterates, the Monorepo project scale (i.e., the number of sub-applications) grows rapidly. Since a single debug or build session often involves multiple sub-applications, this leads to performance degradation.
- Third, Monorepo projects typically have a much longer lifecycle than Polyrepo ones, with many developers contributing. Ensuring the code merged into the repository maintains good maintainability is a challenge.
- Fourth, ByteDance has numerous business lines, known as an “App factory.” How do we provide rich extensibility to meet the needs of these different businesses?
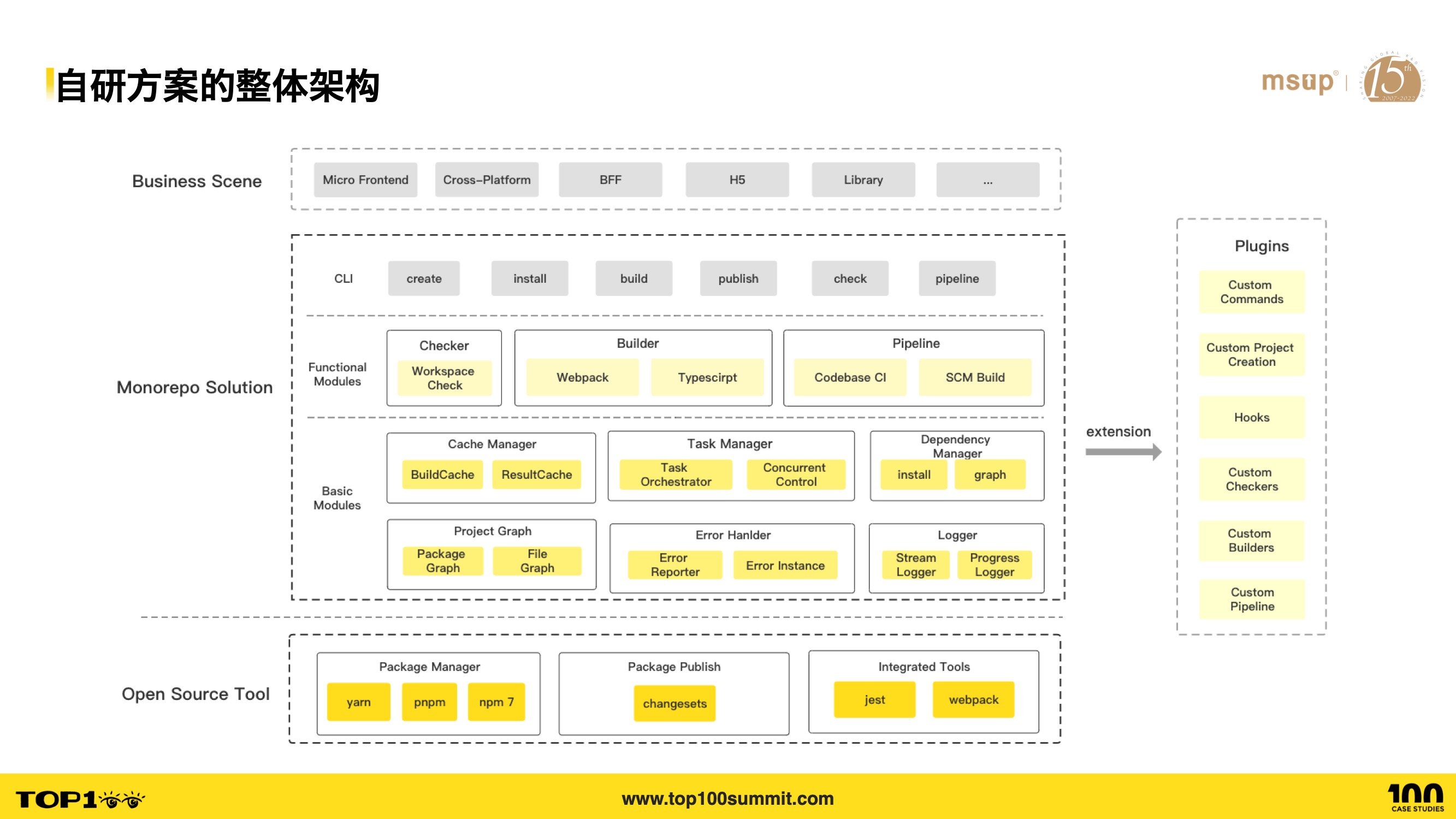
- Here’s an overview of our in-house solution’s architecture, divided into three layers. The bottom layer is the open-source tool layer — the open-source solutions we depend on, including npm package managers, changesets for version management, and sub-application integration tools like jest and webpack.
- The top layer supports various business scenarios: micro-frontends, cross-platform, BFF, H5, Library, etc.
- The middle layer is our in-house solution, also containing three levels: the bottom level encapsulates foundational capabilities like cache management, task management, dependency management, sub-project management, etc.; the middle level provides user-facing functional modules like Checker, Builder, Pipeline, etc.; the top level is the CLI tool providing various commands to leverage Monorepo capabilities.
- On the right side is the plugin-based extensibility provided by our solution.
- Architecture design is not the focus of this talk. What follows is our focus — sharing how this in-house solution addresses the four problems mentioned above.

- Since many users lack sufficient understanding of Monorepo development and are accustomed to Polyrepo or have never even worked with Monorepo before,
- To strengthen user education and lower the onboarding barrier, we closely integrate with ByteDance’s infrastructure:
- Providing a “built-in scaffolding” tool that allows users to create common ByteDance application types with one click
- Providing “CI/CD capabilities” that adapt to ByteDance’s infrastructure for publishing and build pipelines
- Providing “visual extensions” to educate and guide users through a graphical interface
- Let’s elaborate on each of these.
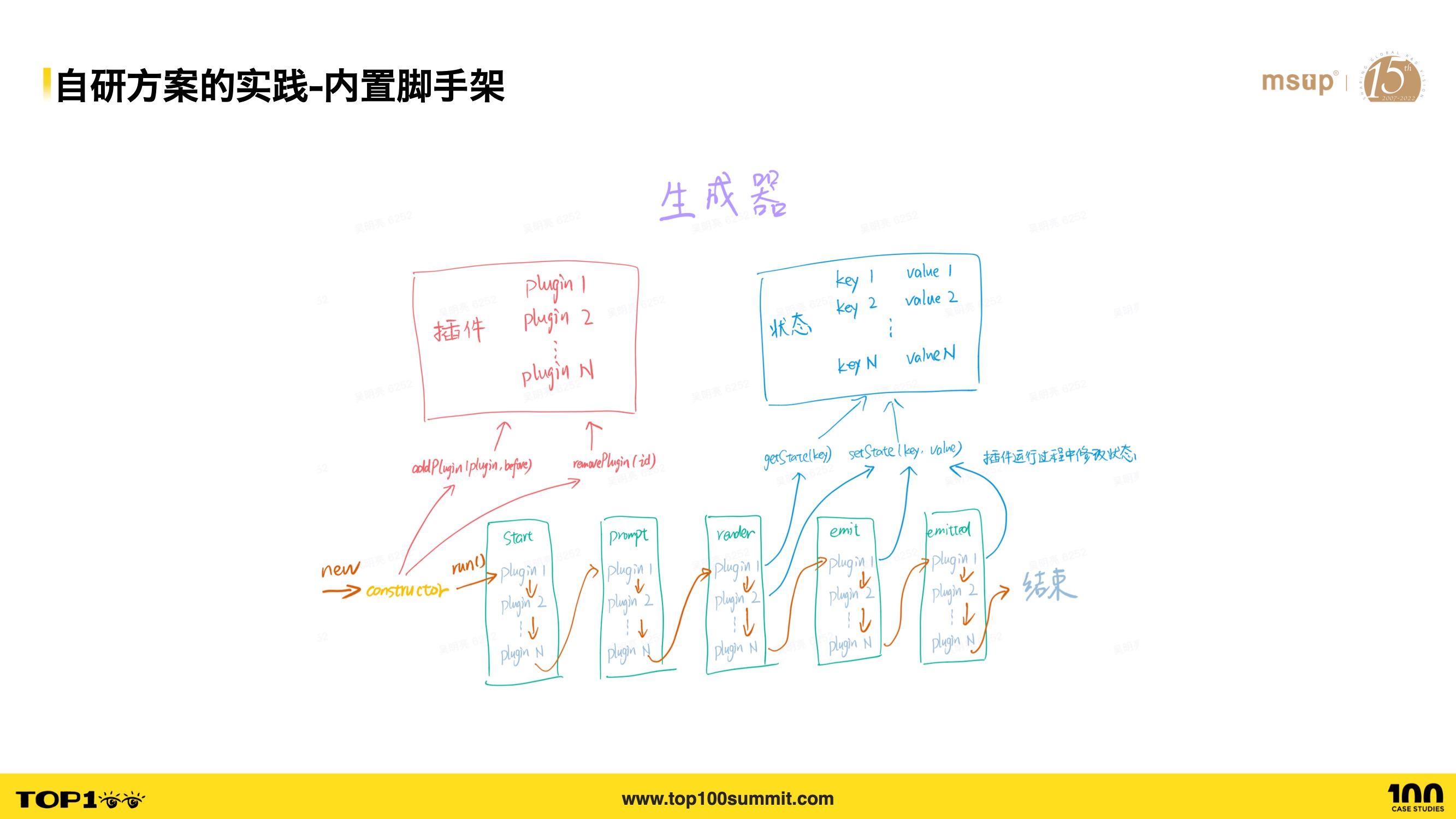
- For built-in scaffolding, we provide a generator template mechanism for sub-project initialization. We integrate templates for common ByteDance application types (Lynx, Gulu, Garfish, component libraries/utility libraries, etc.), and users can also implement their own templates. Templates can be at the project level or component level.
- The diagram shows the generator’s architecture, consisting of 5 stages. For example, the prompt stage collects user CLI input, the render stage renders template files, and the emit stage generates template files. Through a plugin mechanism, each plugin can handle its logic in these 5 stages. We provide plugins for Git repository creation, SCM creation, npm dependency installation, etc.
- With this generator design, users can customize out-of-the-box templates for their business lines, creating projects with Git repositories and SCM build configurations in one click, reducing the cost of project creation.
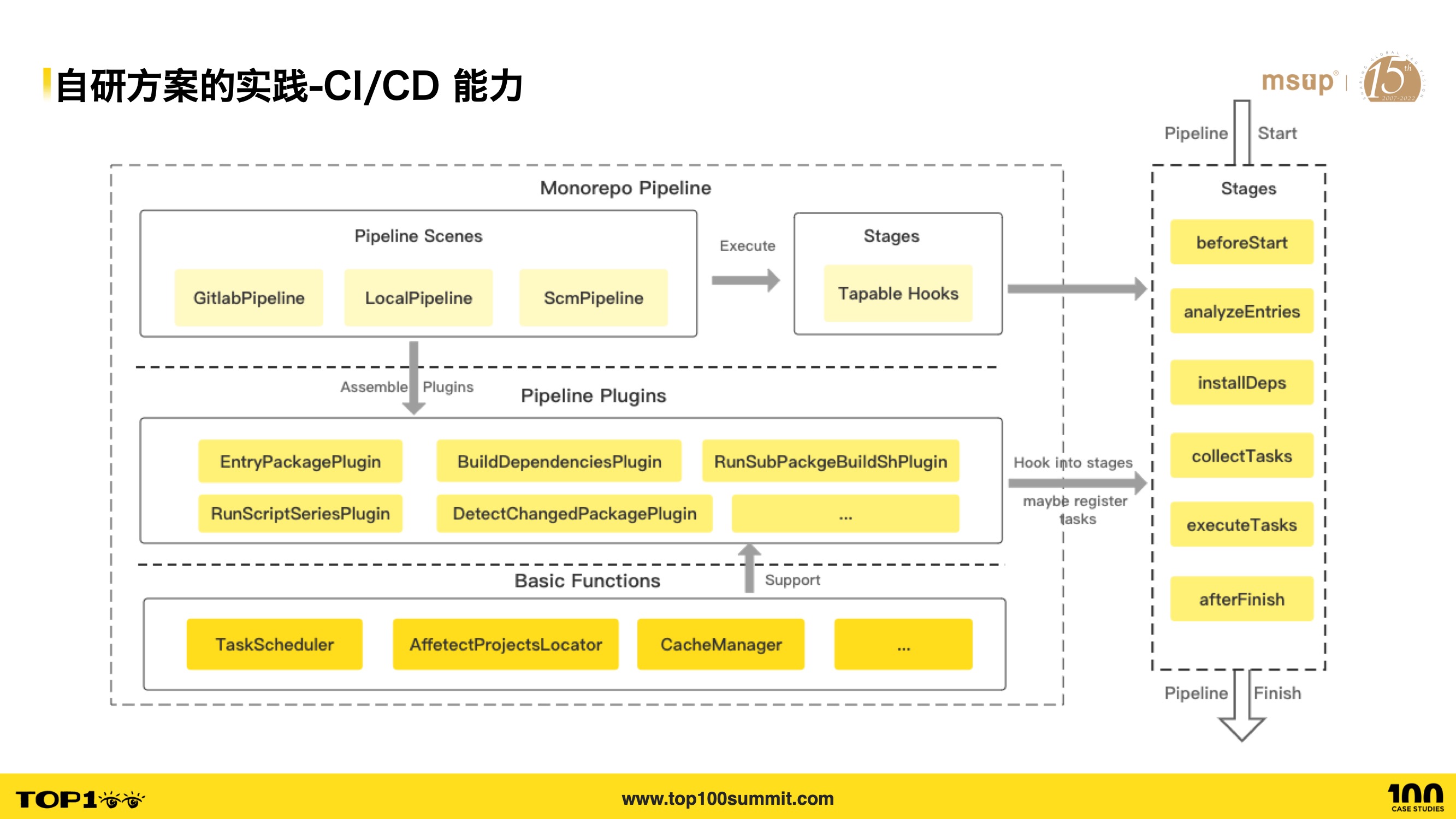
- Next, let’s look at the CI/CD capabilities. Here’s the architecture diagram — it’s also implemented through a plugin mechanism. For example, EntryPackagePlugin is used for entry application detection, BuildDependenciesPlugin for build dependencies, and RunSubPackageBuildShPlugin for executing sub-application shell scripts.
- To support multiple environments, each scenario has a corresponding Pipeline, such as GitlabPipeline and SCMPipeline. Simply put, a set of plugins is maintained for each scenario, and when a scenario executes, the corresponding Pipeline is invoked. Each Pipeline goes through the same stages.
- The stage list is shown on the right. The analyzeEntries stage analyzes dependencies to determine which code has changed, and the collect tasks stage schedules sub-project task pipelines.
- Through plugin set customization, the current Pipeline mechanism works out of the box for SCM and Gitlab CI scenarios and is easy to extend for future scenarios.
- This mechanism supports Gitlab CI automated release pipelines and SCM build pipelines, greatly reducing the cost of integrating applications with release and build platforms.
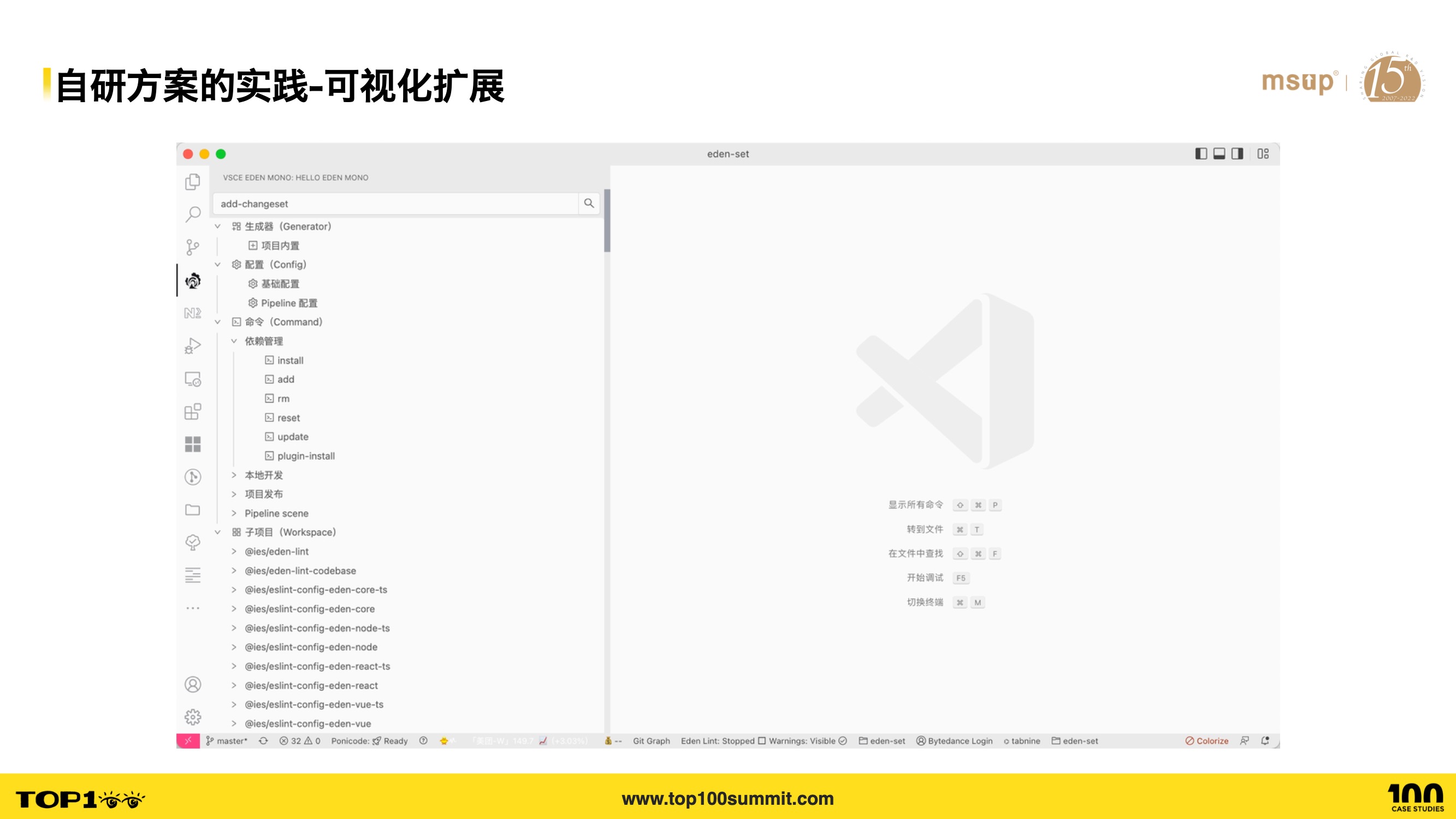
- For visual extensions, we educate and guide users through a graphical interface, providing quick operations to create sub-applications, invoke various commands, search sub-applications, configure Monorepo settings, etc.
- This lowers the onboarding cost for new users and reduces the cognitive burden of memorizing commands.

- Since Monorepo inevitably leads to rapid growth in the number of sub-applications, and a single debug or build session often involves multiple sub-applications, this causes performance degradation. We need specialized solutions to ensure debugging and build performance.
- To address performance degradation caused by increasing scale, we improve build efficiency through multiple approaches:
- Supporting “task parallelism” with maximum batch task parallel acceleration
- Supporting “multi-level caching” for dependency installation, build artifacts, test results, etc.
- Supporting “on-demand building” based on the dependency graph and the impact scope of code changes
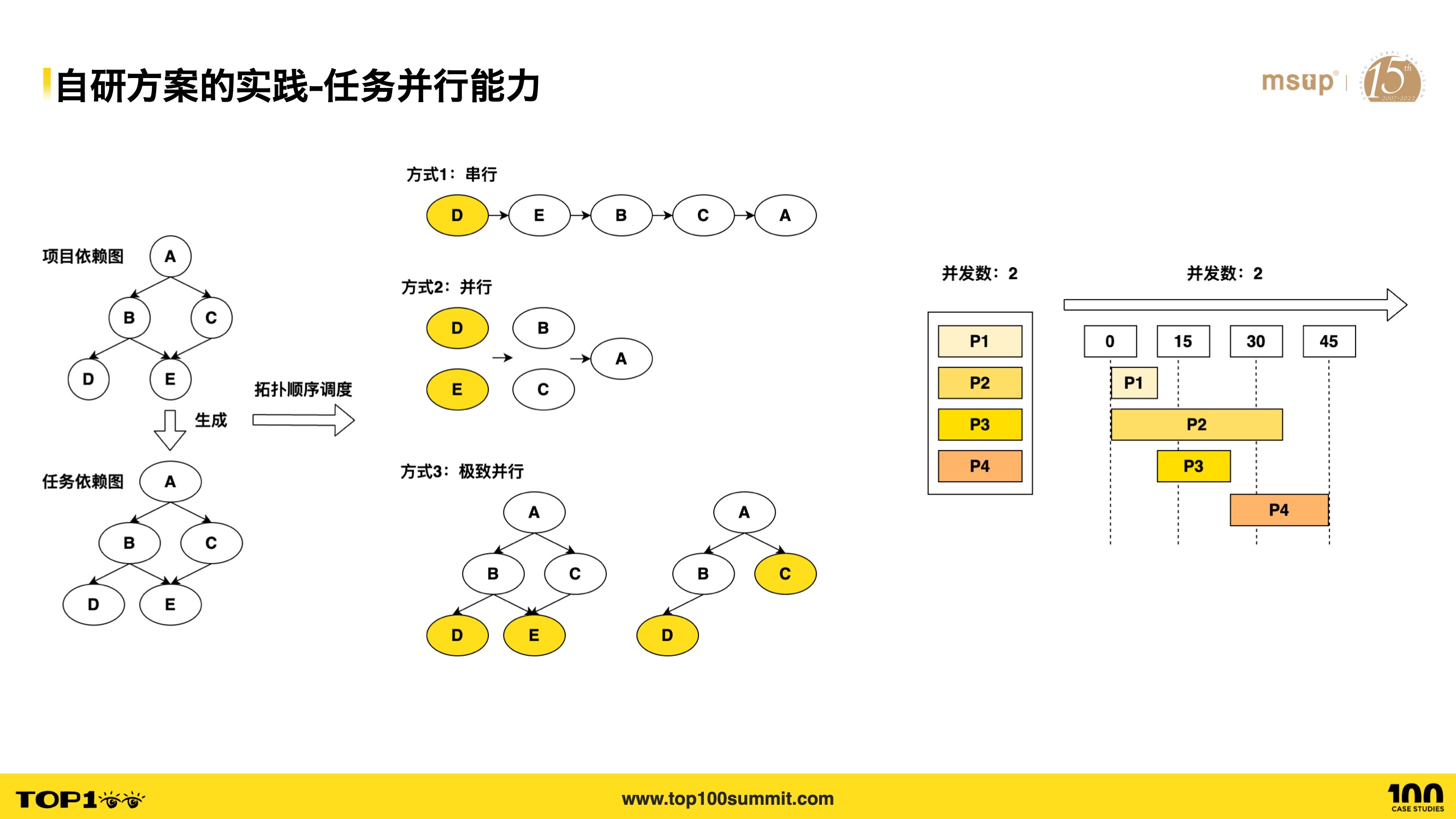
- Let’s see how we implement task parallelism!
- As shown in the diagram, we convert sub-project dependency relationships into a task dependency graph and schedule tasks based on it.
- Looking at the task dependency graph in the bottom left, the build order must satisfy this requirement: upper-level projects depend on the completion of lower-level project builds.
- OK, let’s look at Approach 1 — the most straightforward way: serial execution in the order DEBCA. This satisfies the build requirement but has low performance since D and E can be parallelized. So Approach 2 parallelizes DE and BC, reducing 5 steps to 3. But this optimization isn’t optimal enough — task C doesn’t depend on task E’s completion, yet in Approach 2, task C has to wait for both D and E to finish.
- This leads to Approach 3: after task E completes, D and C can execute in parallel. Considering that too many concurrent sub-project tasks could overload the CPU, we also include concurrency control — for example, with 4 tasks to execute and a maximum concurrency of 2, as shown in the timing diagram on the right.
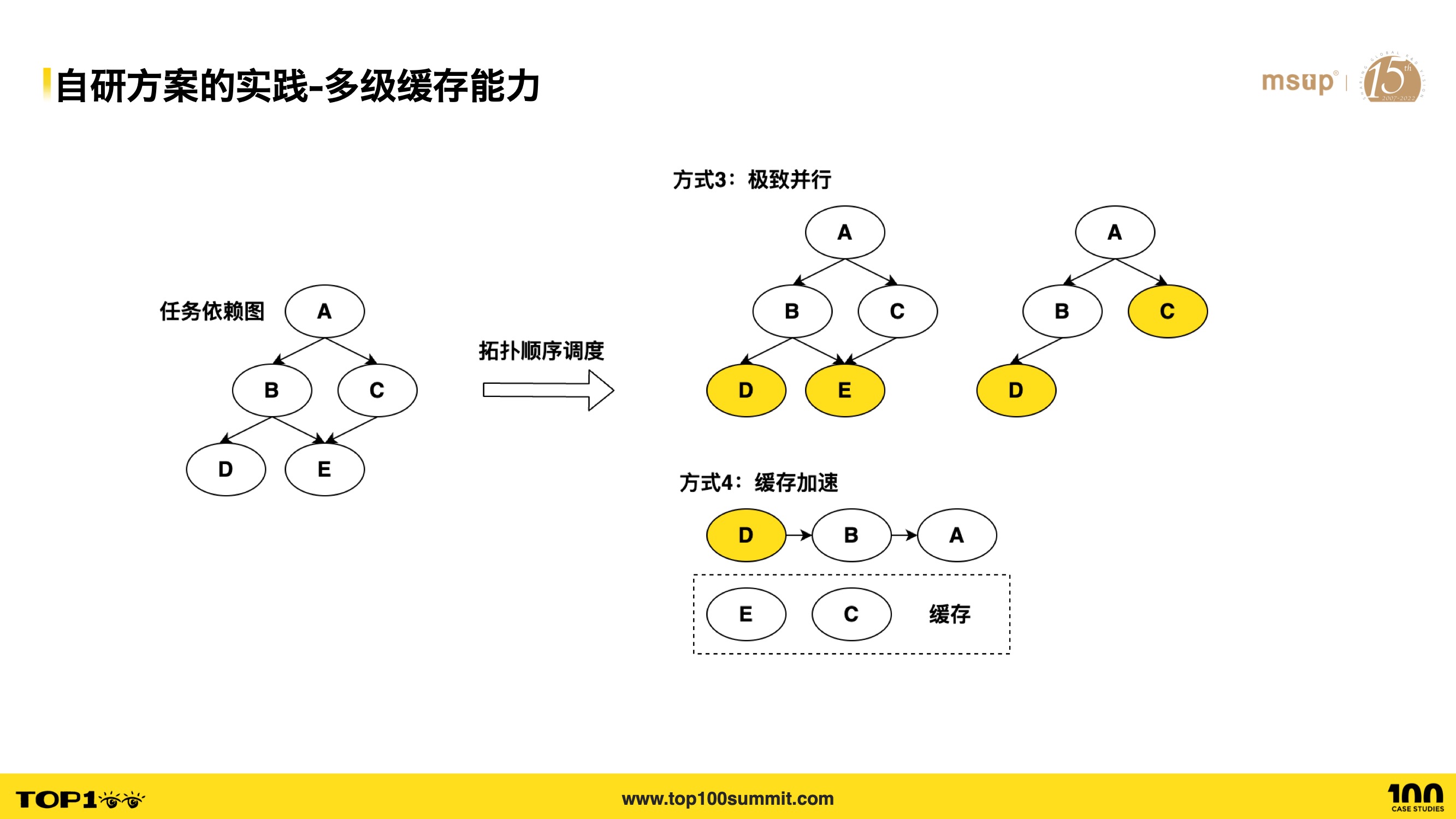
- Next, let’s look at multi-level caching. As a monorepo grows in size, every development or release cycle may involve several sub-projects. Rebuilding all of them every time significantly slows down build and deployment times.
- We provide the ability to cache build artifacts both locally and remotely. When related sub-projects haven’t had code changes, previous build artifacts are reused to reduce build time. Beyond build tasks, other operations like unit test execution also cache results, allowing test tasks to be skipped.
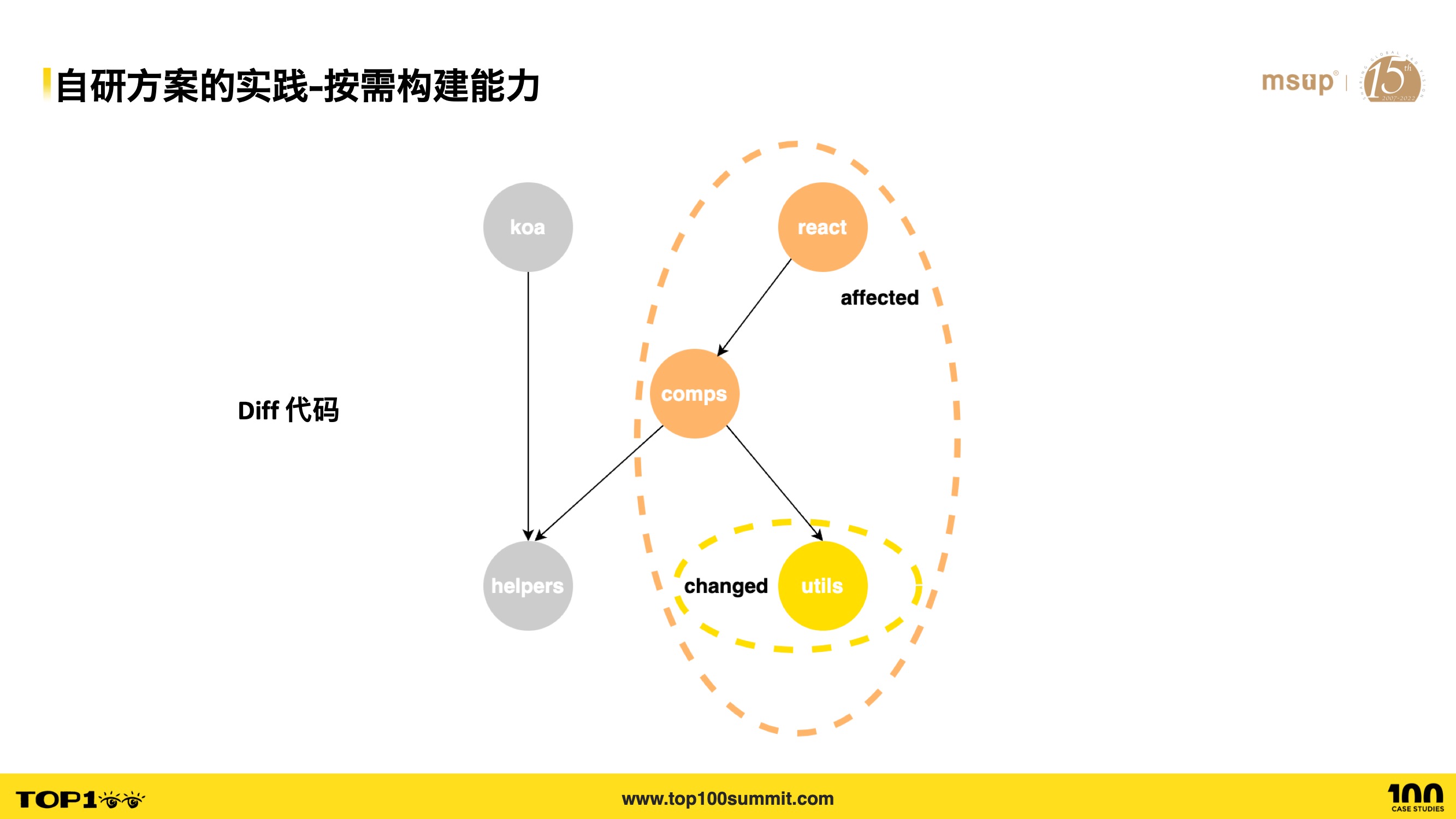
- For on-demand building, we support executing CI processes based on the impact scope. By diffing changed code and performing dependency analysis, we identify affected projects across the entire Monorepo and execute their CI pipelines. Otherwise, every CI run would build all sub-projects in their entirety.
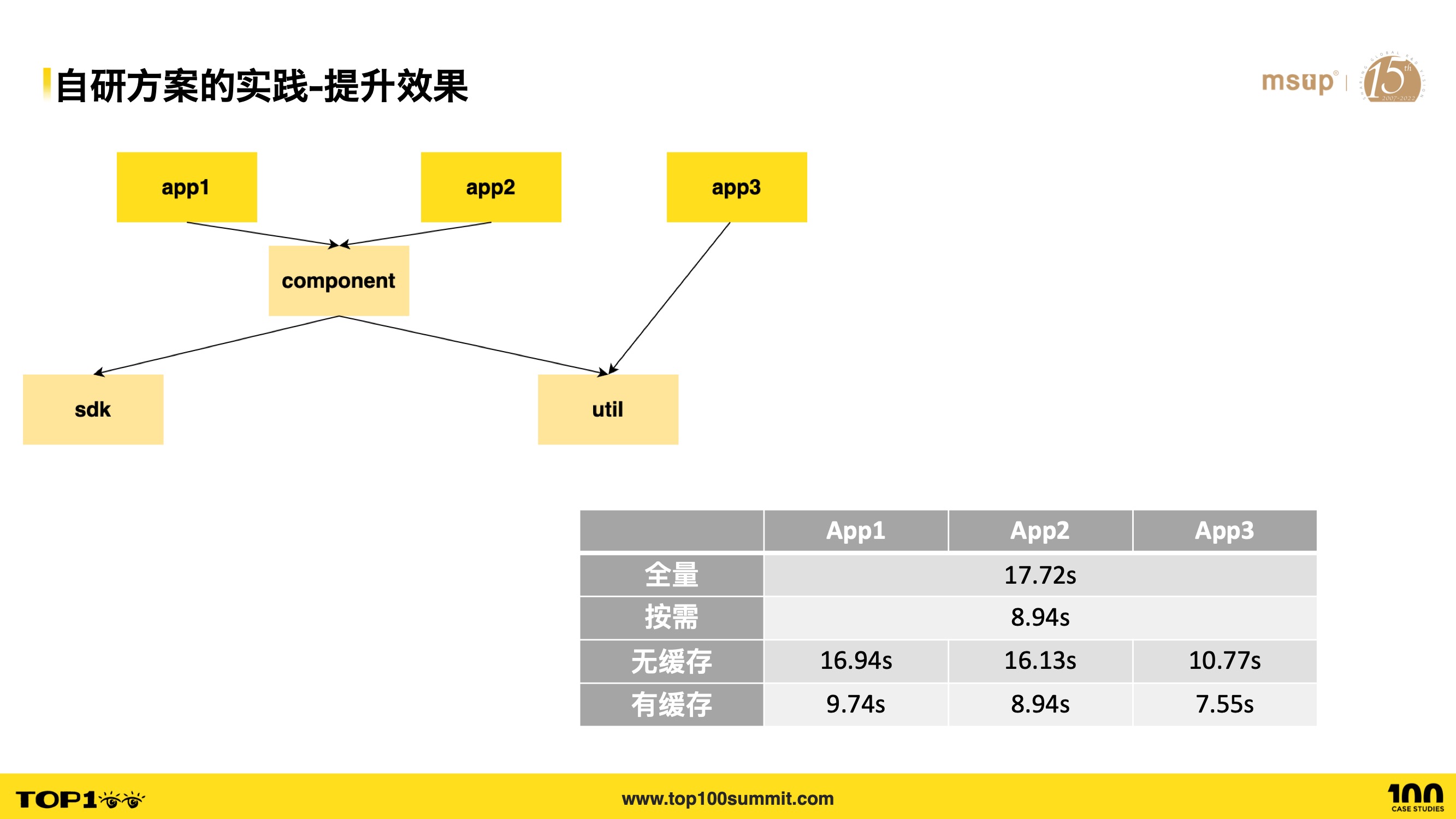
- Here’s a simple Monorepo example with dependency relationships as shown:
- Full build of all applications takes approximately 17.72 seconds
- If only the component module is changed, on-demand building requires building only component, app1, and app2, taking 8.94 seconds — a 50% time saving
- Without caching, building just App1, App2, and App3 takes between 10.77 and 16.94 seconds
- With caching (e.g., component, sdk, and util already built), building App1, App2, and App3 individually takes between 7.55 and 9.74 seconds — approximately 45% time saving

- Since Monorepo means many engineers of varying skill levels developing in the same repository, and the amount of new code added each week is massive, we need to ensure code quality.
- For code degradation prevention, we use a Checker mechanism for various standard checks:
- Supporting “built-in Checkers” to ensure basic project maintainability
- Supporting “custom Checkers” so users can write checks based on their team’s standards
- Supporting “auto-fix” to automatically fix code or configurations that don’t meet standards

- We’ve built in multiple Checkers to ensure basic maintainability, such as unified dependency versioning which checks whether the same dependencies across projects have consistent versions in their package.json files, and so on.
- Taking unified dependency versioning as an example — we all know that different versions of the same dependency across projects can cause issues. For instance, if the React versions in components and the app are inconsistent, you’ll get React hooks errors. Applying the first Checker here can detect this issue and automatically fix it to a unified version.

- What if the built-in Checkers don’t meet users’ standards requirements? We also provide the ability to create custom Checkers. Within each Checker, we inject context information such as the current Monorepo project’s configuration and dependency graph, enabling Checker developers to verify whether the current project meets standards using this information.

- After detecting issues, some violations can actually be resolved through auto-fix. Just like ESLint, we also support automatic code fixing.

- Since ByteDance has numerous business lines, known as an “App factory,” different businesses have various extension requirements for Monorepo.
- To address these different business extension needs, we provide flexible extensibility through a plugin mechanism that supports custom commands, Checkers, generators, and exposes hooks throughout the entire lifecycle.

- The above covers the problems we encountered during the implementation of our in-house solution. Next, let’s briefly discuss the overall adoption status.

- In ByteDance’s frontend domain, our in-house solution among all Monorepo projects:
- Accounts for 25% of repositories, with the absolute number of repositories using our solution already in the thousands
- Monthly active share of 47%, with the total number of sub-applications (when flattened) approaching the number of multi-repo projects
- Weekly npm package downloads exceeding 140,000+
- In ByteDance’s frontend domain, whether by repository share, monthly active share, or download volume, our in-house solution ranks #1 among Monorepo tools


- Through our in-house solution development, we’ve built an efficient, extensible, out-of-the-box Monorepo solution that effectively serves thousands of Monorepo projects at ByteDance, receiving positive business feedback. Our current Monorepo solution faces several core challenges:
- First, local task scheduling performance bottleneck — giant Monorepo repositories are beginning to experience dependency installation and build speed issues, requiring more extreme performance and experience optimization.
- Second, lack of cache management capabilities — how to track and resolve low cache hit rate issues.
- Third, dependency readability issues — the current text-based dependency structure is hard to understand, making effective dependency management difficult.
- Our solutions to these challenges:
- For performance: we will develop our own dependency installation logic to accelerate installation; strengthen task scheduling performance (e.g., sub-project task scheduling and remote task execution capabilities) to accelerate builds.
- For caching: we will develop a cache SDK to provide cache management and reuse capabilities, tracking and improving cache hit rates.
- For dependency management: we will provide development assistance tools to manage complex dependency relationships through visualization.

Slides Attachment
Frontend Monorepo Practices at ByteDance
http://quanru.github.io/2022/12/31/Frontend-Monorepo-Practices-at-ByteDance

