Frontend Engineering Practices at ByteDance
Invited to speak at the 2023 WOT Global Technology Innovation Conference organized by 51CTO.
Background
- Invited to speak at the 2023 WOT Global Technology Innovation Conference organized by 51CTO.
- Frontend Engineering Practices at ByteDance: Significantly Improving Build and Maintenance Efficiency for Giant Applications - 51CTO.COM
About This Topic


Slides


- Good morning everyone, I’m Lin Yibing. Today I’ll be sharing on the topic of “Frontend Engineering Practices at ByteDance.”

- Let me briefly introduce myself. I’m a frontend architecture engineer from the Web Infra team, with years of experience in frontend engineering. I’m dedicated to helping frontend engineers better manage and govern their projects. Currently, I’m responsible for the design and implementation of engineering governance solutions.

- Today’s talk covers four parts:
- First, we’ll analyze the “current trends in the frontend development landscape” and identify the new challenges facing ByteDance’s frontend development.
- Second, we’ll share the practices we’re currently applying to address these new challenges.
- Third, we’ll share the overall adoption status of our in-house solutions at ByteDance.
- Finally, we’ll summarize and look ahead at the development patterns of frontend engineering.
- OK, before we dive in, let’s first look at “What is frontend engineering?”
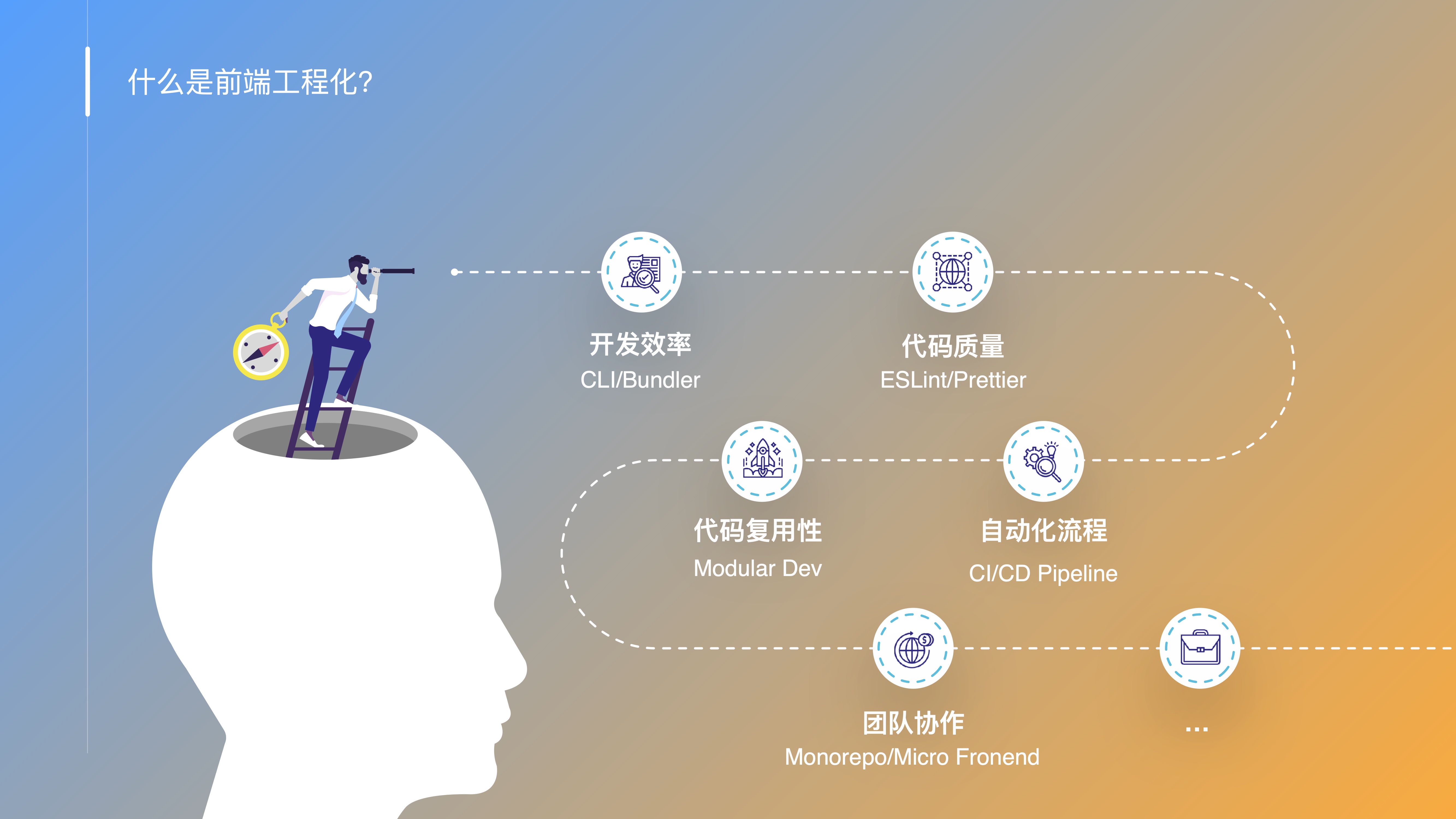
- Frontend engineering refers to adopting a series of technical approaches and tools in the frontend development process to improve development efficiency, ensure code quality, enhance code reusability, enable automated workflows, and facilitate team collaboration. It is an indispensable part of modern frontend development.
- I want to specifically note that this talk is not about frontend engineering as a whole, but rather about the “new practices” we’ve adopted to address “new challenges” arising from current “new trends.” Let’s see what new trends have emerged in frontend development.
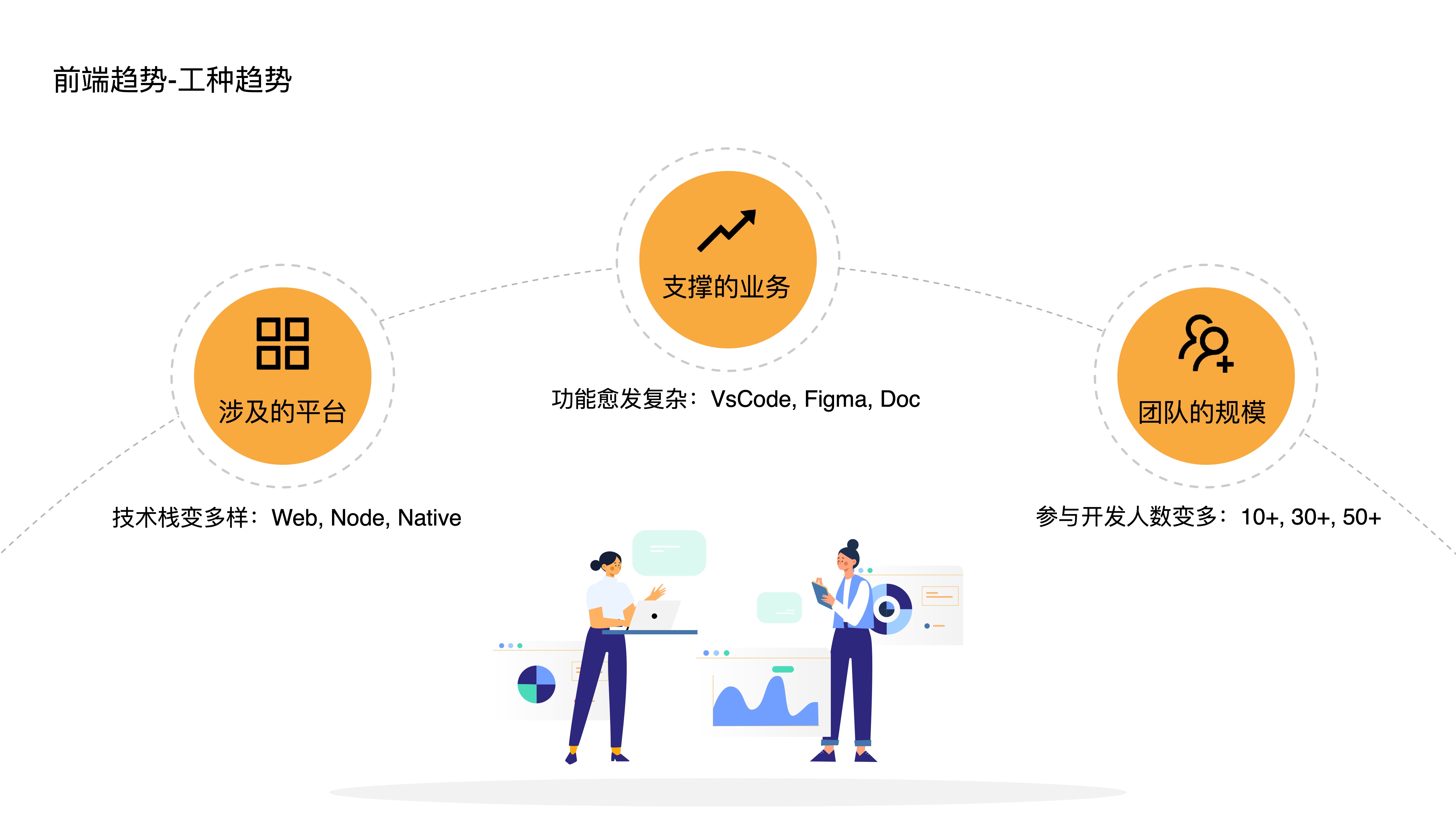
- First, the trends in frontend roles:
- The first trend is that the number of platforms keeps growing — Web, Node, native clients, cross-platform, and more.
- The second trend is that the business applications they support are becoming more numerous and complex, especially with the emergence of frontend-heavy interactive applications in recent years.
- The third trend is that, inevitably driven by the first two, frontend team sizes continue to grow.
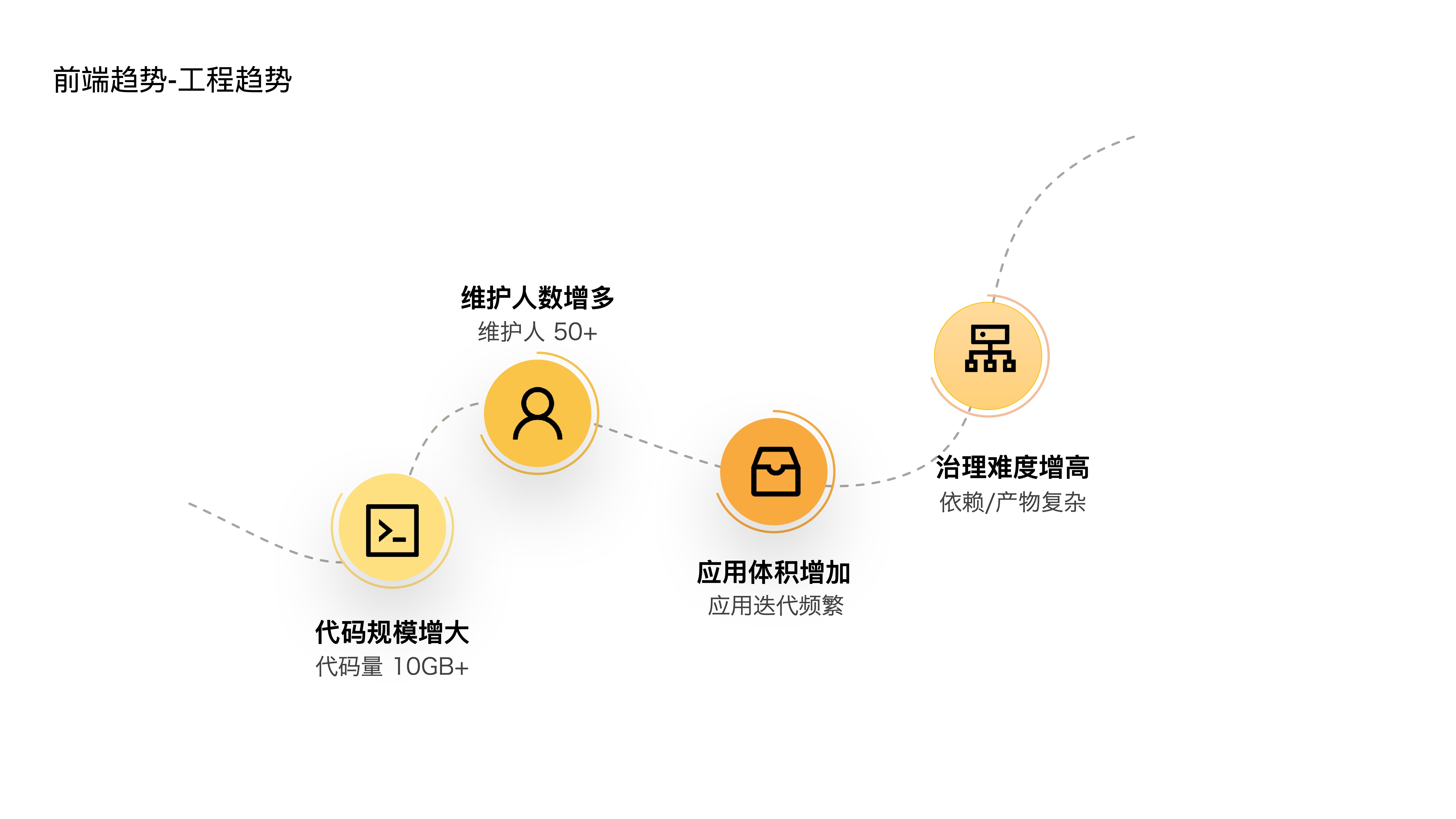
- These three trends have objectively led to four trends in frontend engineering:
- First, codebase sizes are increasing — we already have large-scale projects with over 10GB of code internally, and the number of upstream and downstream dependency projects for a single application is also very large.
- Second, the number of maintainers is growing — a single project can have anywhere from a dozen to forty or fifty people.
- Third, application sizes are increasing — as features iterate, applications become increasingly bloated.
- Fourth, governance difficulty is rising — complex dependency relationships and build artifacts are hard to govern and diagnose.
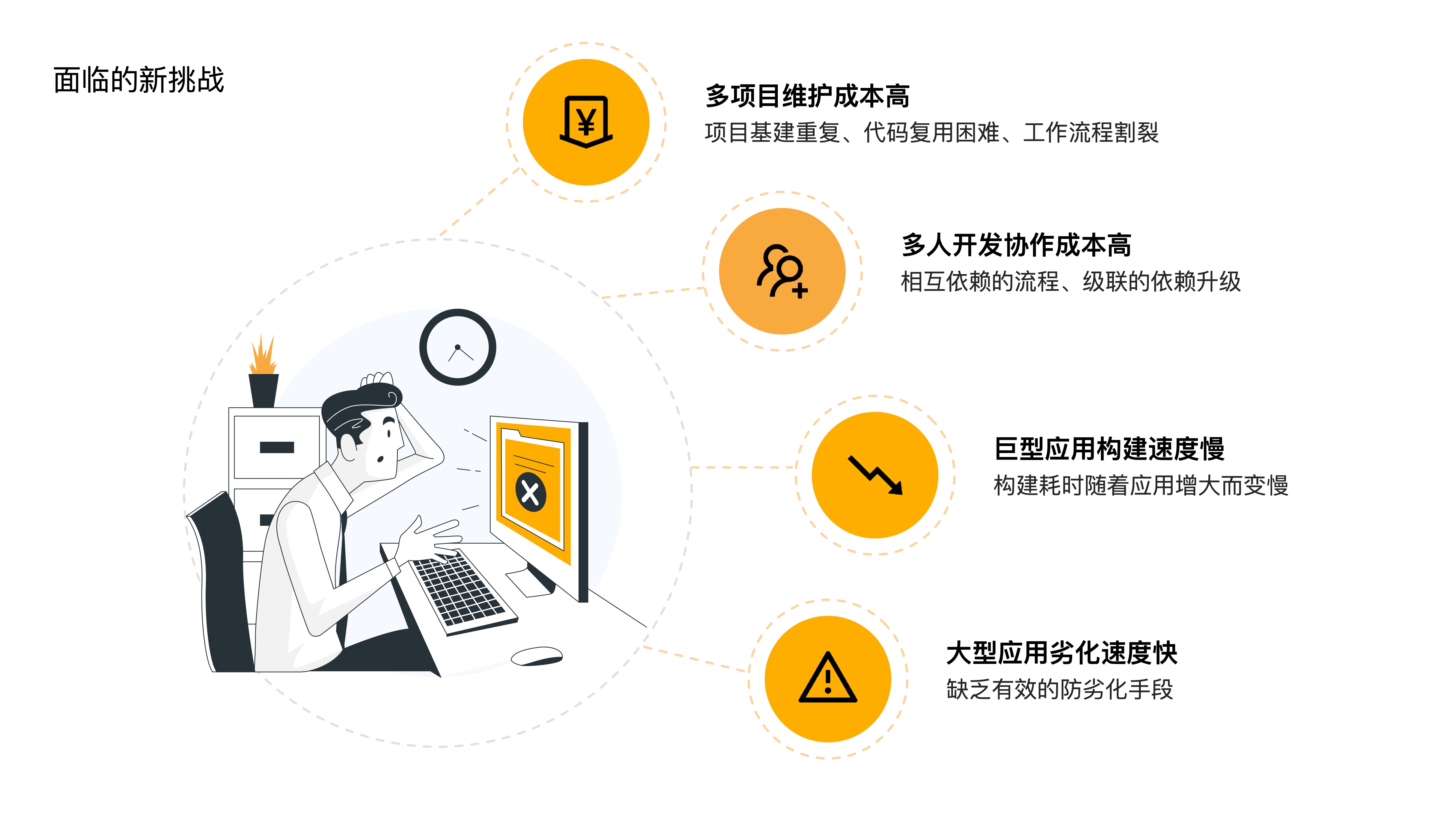
- Given these trends, what new challenges does our frontend development face? There are mainly four:
- First, high multi-project maintenance costs — repetitive infrastructure, difficult code reuse, fragmented workflows, etc.
- Second, high multi-person collaboration costs — interdependent processes and cascading dependency upgrades increase collaboration overhead.
- Third, slow build speeds for giant applications — build times grow as applications get larger.
- Fourth, rapid degradation of large applications — we lack effective anti-degradation measures.
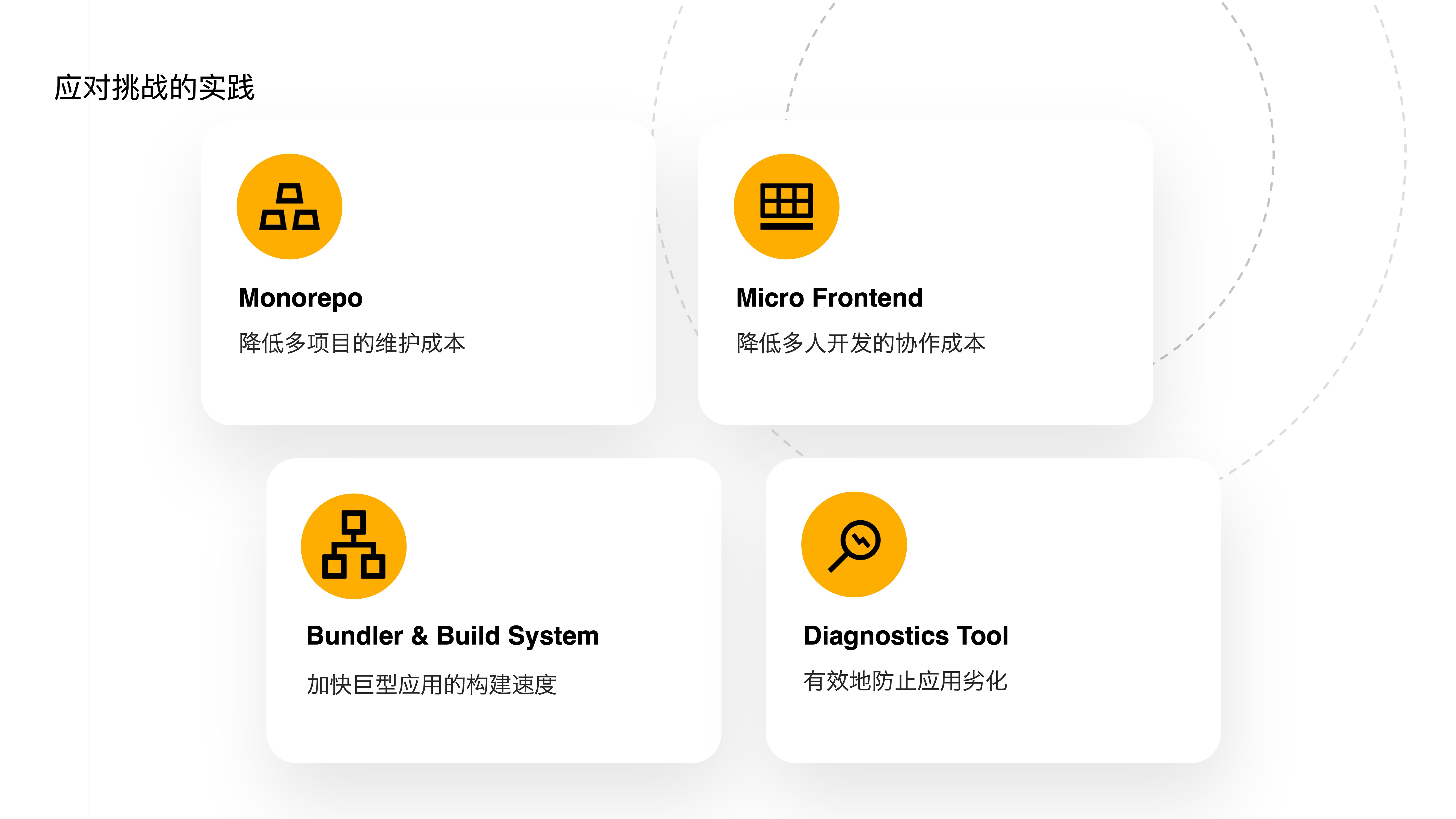
- To address these new challenges, we’ve invested in the following tools:
- First, an in-house Monorepo tool to reduce multi-project maintenance costs.
- Second, upgrading our existing micro-frontend framework to further reduce multi-person collaboration costs.
- Third, developing a Bundler and Build System to accelerate build speeds for giant applications.
- Fourth, providing diagnostics tools to effectively prevent application degradation.
- Let’s dive into each of these four topics and how we’ve put them into practice.
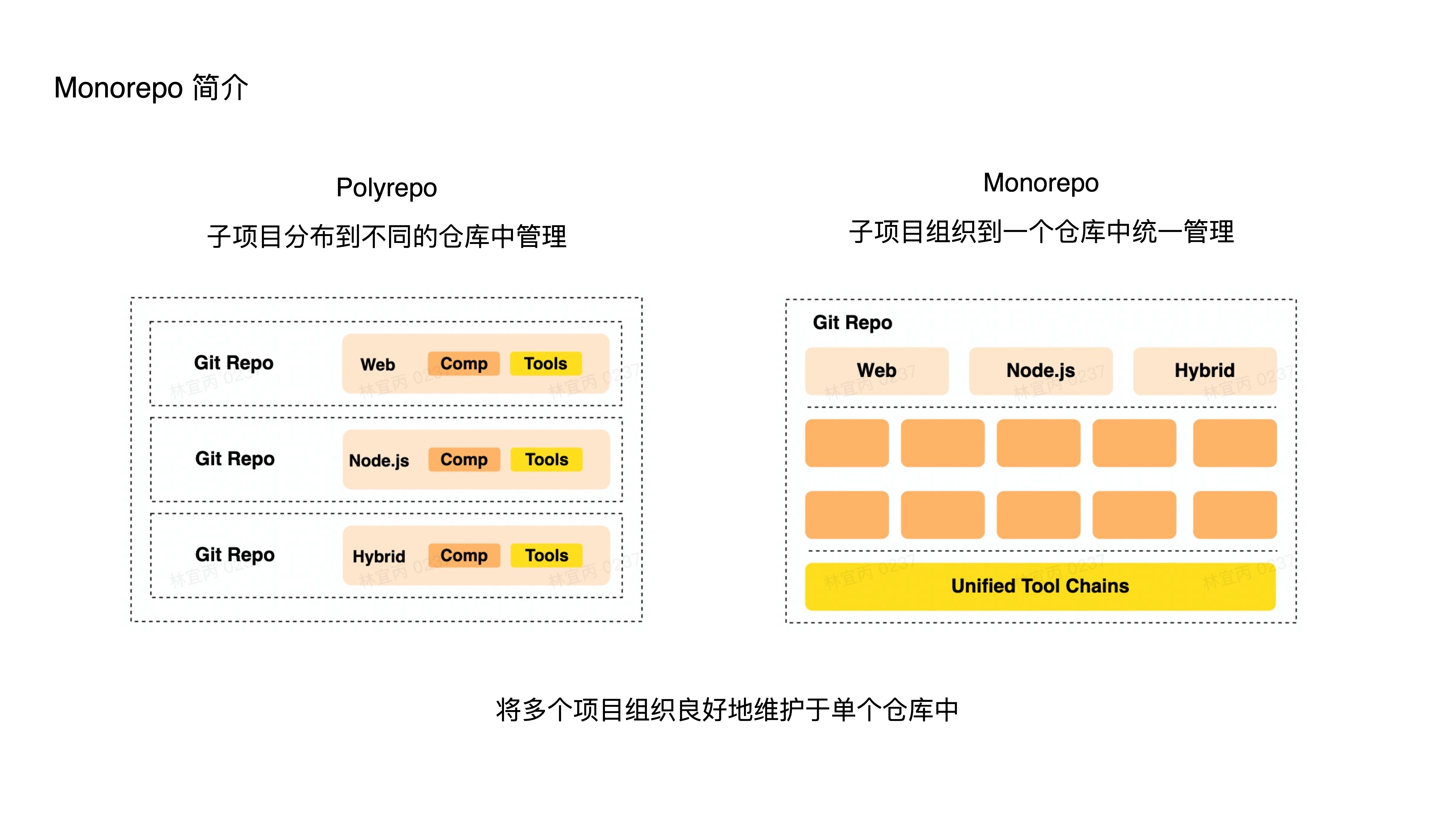
- What is Monorepo?
- It’s a source code management pattern where multiple projects are managed within a single repository.
- The opposite is the Polyrepo pattern, where each project has its own independent repository.
- In short, Monorepo means maintaining multiple different projects in a single repository with well-organized relationships.

- How does Monorepo reduce multi-project maintenance costs? Through:
- Reusing infrastructure — letting developers refocus on the application itself
- Code sharing — enabling low-cost code reuse
- Atomic commits — using automated multi-project workflows
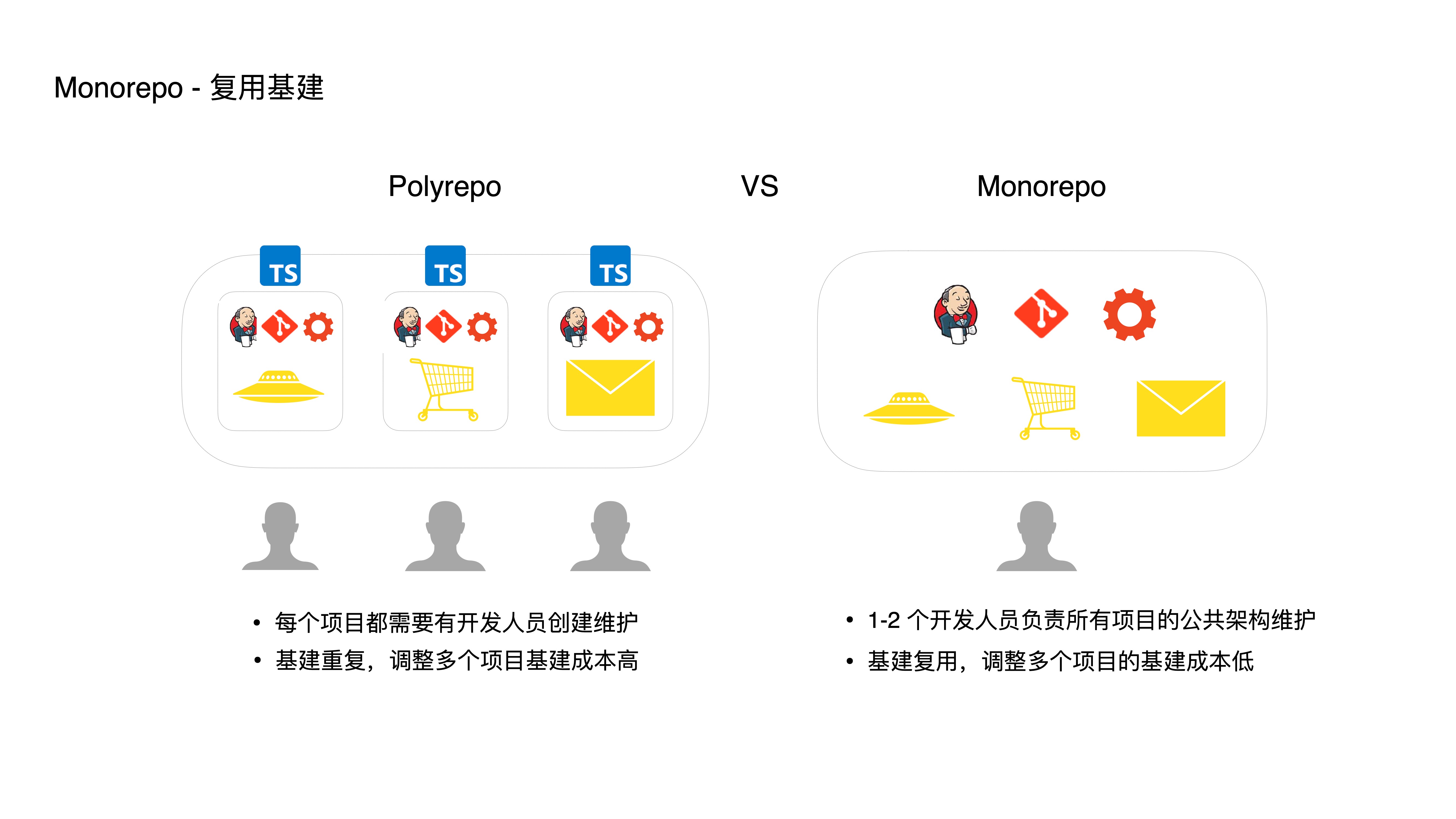
- First, by reusing infrastructure, developers can refocus on the application itself:
- In the traditional Polyrepo model, each project needs developers to create and maintain it. In Monorepo, only one or two developers need to set up the Monorepo project, and all projects can be maintained in a unified way within a single repository. By reusing a single set of infrastructure (CI configuration, lint rules, build scripts, etc.), multi-project maintenance costs are reduced.
- Furthermore, reusing infrastructure makes unified refactoring and upgrades convenient. For example, if you want to add type checking in CI for all projects to improve quality, in Polyrepo you’d need to modify every single project — which is very costly. In Monorepo, infrastructure adjustments and maintenance can be easily applied across multiple projects.
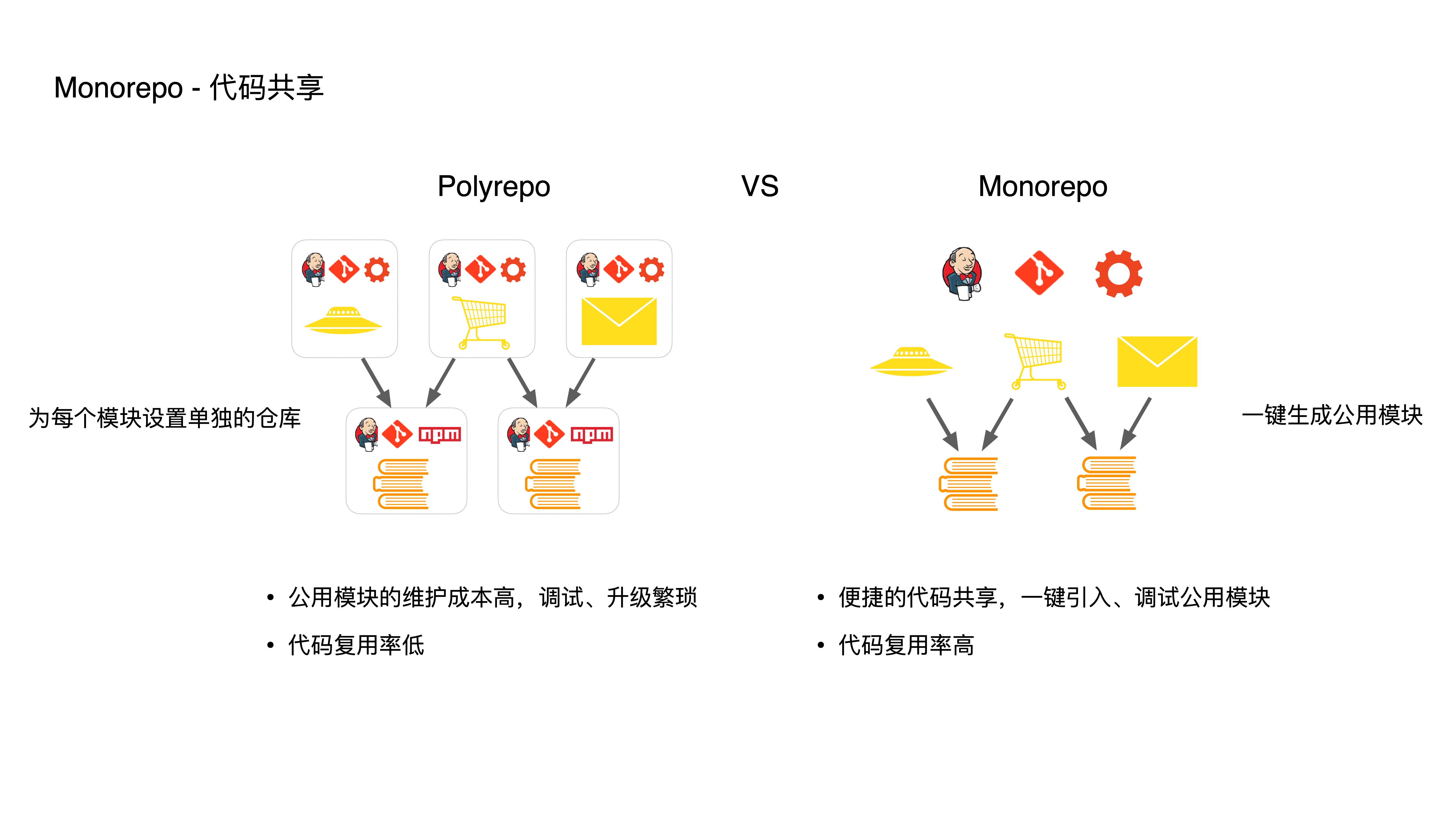
- Second, through code sharing, developers can reuse code at low cost:
- In Polyrepo, maintaining shared modules is costly. Debugging is cumbersome — shared module debugging requires manual npm link with the current project. With many shared modules, this becomes extremely inefficient.
- Upgrading shared modules is also cumbersome — you need to manually manage dependencies, upgrade bottom-level modules first, publish them, then upgrade top-level modules. If something goes wrong, you have to redo the entire process.
- In Monorepo, you can create shared modules with one click. Top-level modules can import shared modules for development and debugging with one click. Changes to bottom-level modules are immediately visible to upper layers, without going through linking or npm publishing, greatly reducing repetitive work and lowering the cost of extracting new reusable code. This encourages developers to do more extraction work, which in turn improves code reuse rates.
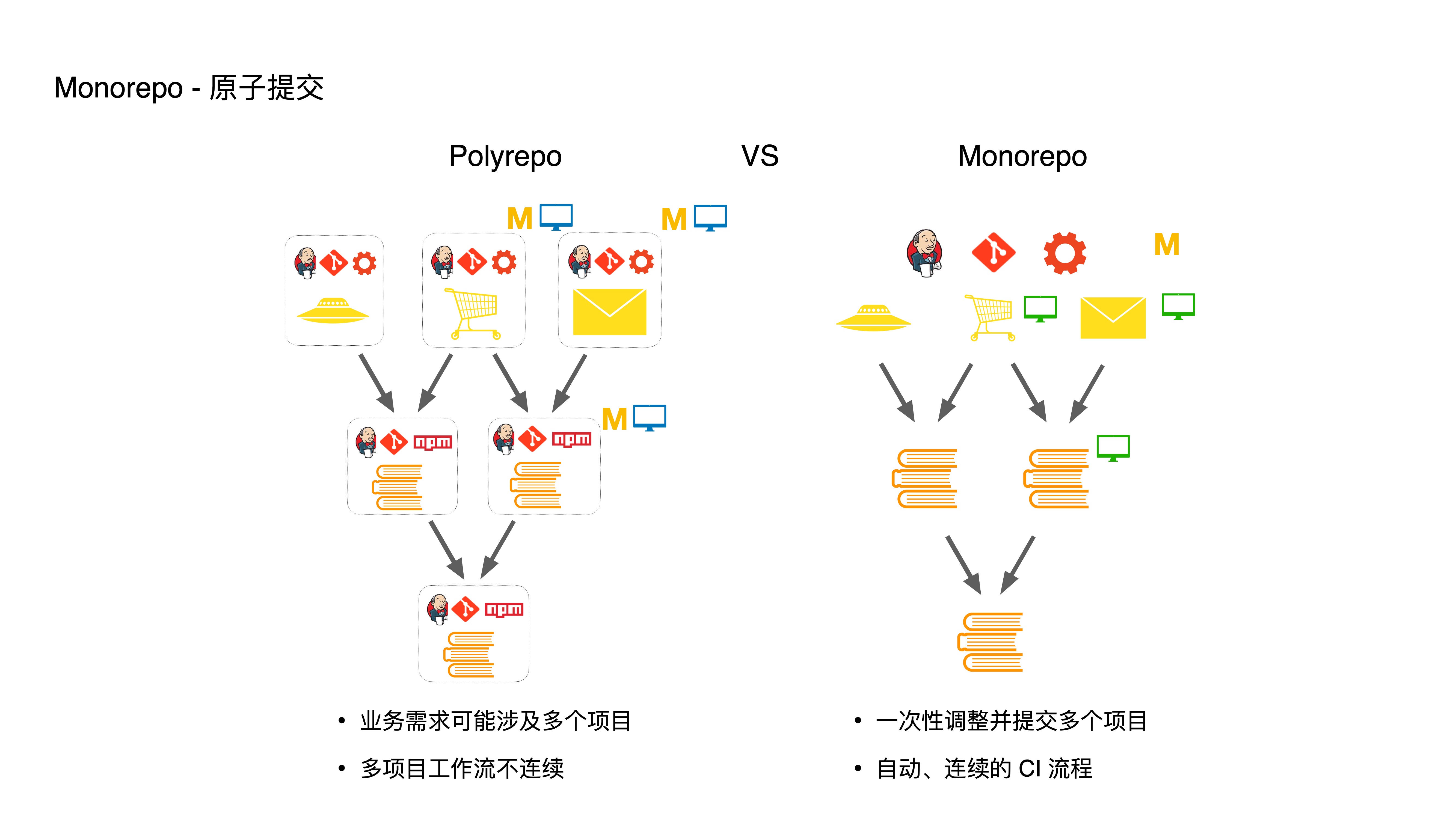
- Third, through atomic commits, developers enjoy automated multi-project workflows:
- If a business requirement involves multiple projects, in Polyrepo you’d need to modify three projects as shown — first modifying and committing bottom-level modules, running CI for each, then updating dependencies for top-level modules, and running CI again. This entire process is very cumbersome and discontinuous.
- In Monorepo, we can directly adjust and commit multiple projects at once. CI and release processes are also handled in one go, automating the multi-project workflow.
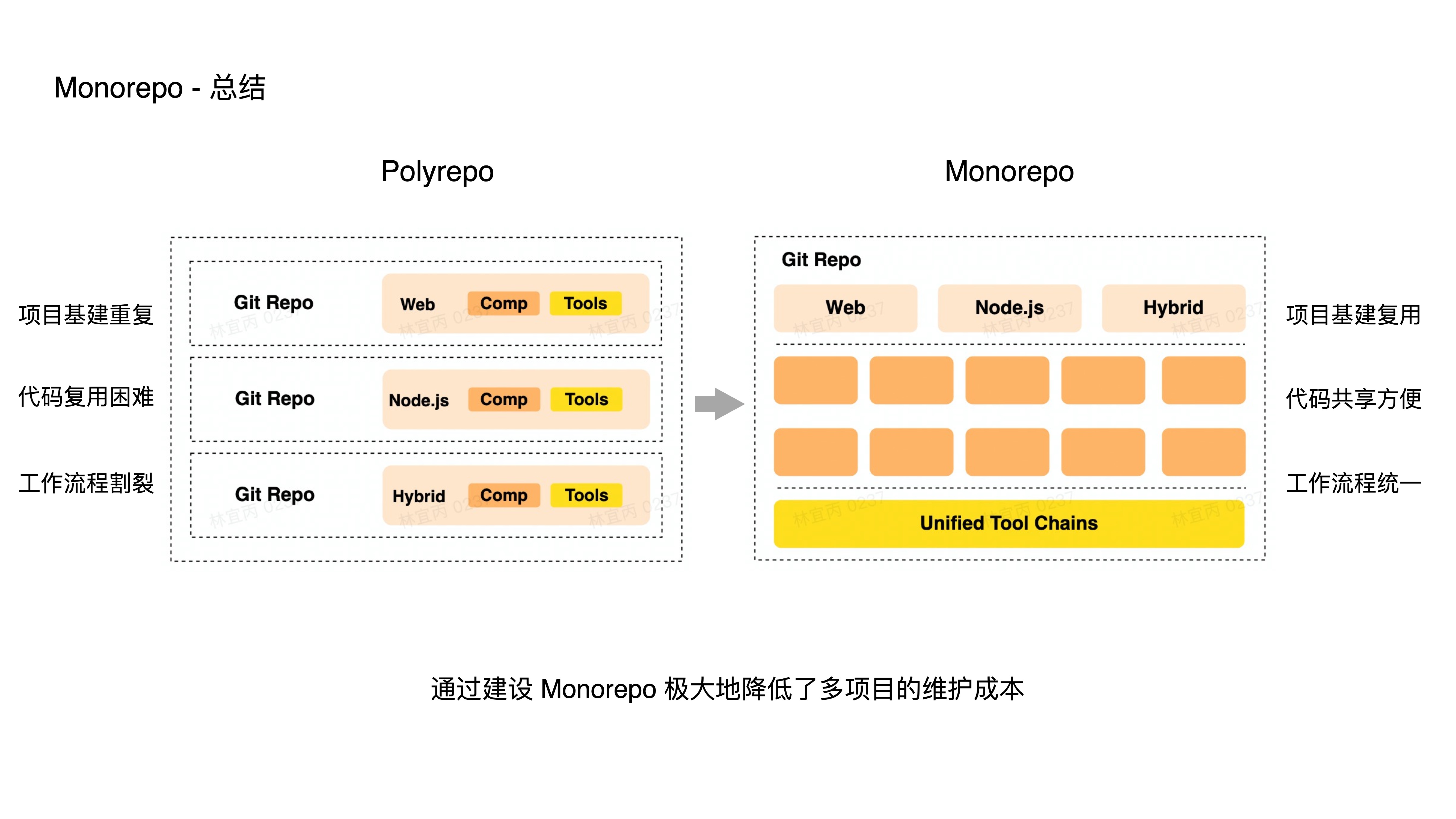
- A brief summary:
- In Polyrepo mode, each project has its own infrastructure, code reuse is difficult, and workflows are fragmented. In Monorepo, multiple projects can share a single set of infrastructure, conveniently share code, and use consistent workflows.
- In many cases, a team’s projects are not isolated but interconnected. Monorepo conveniently organizes these projects into a single large repository for maintenance, greatly reducing multi-project maintenance costs.

- Next, let’s share the engineering practices around Bundler and Build System. Whether it’s a single-repo or multi-repo project, as code scale and the number of sub-applications increase, build performance degrades. To address this, we’ve built both a Bundler and a Build System.
- The Bundler addresses slow build speeds for individual monolithic applications.
- The Build System addresses slow build speeds within Monorepo.

- In the frontend domain, a Bundler is a tool that packages multiple frontend assets (such as JS, CSS, images, etc.) into one or more files so that browsers can run them directly.
- Common Bundler tools include Webpack, Rollup, Vite, Parcel, and Esbuild.

- Let me introduce our in-house Rspack Bundler. It’s a high-performance build engine based on the Rust language, with interoperability with the Webpack ecosystem.
- From this introduction, we can see that Rspack has two key features: high performance and compatibility with the Webpack ecosystem.
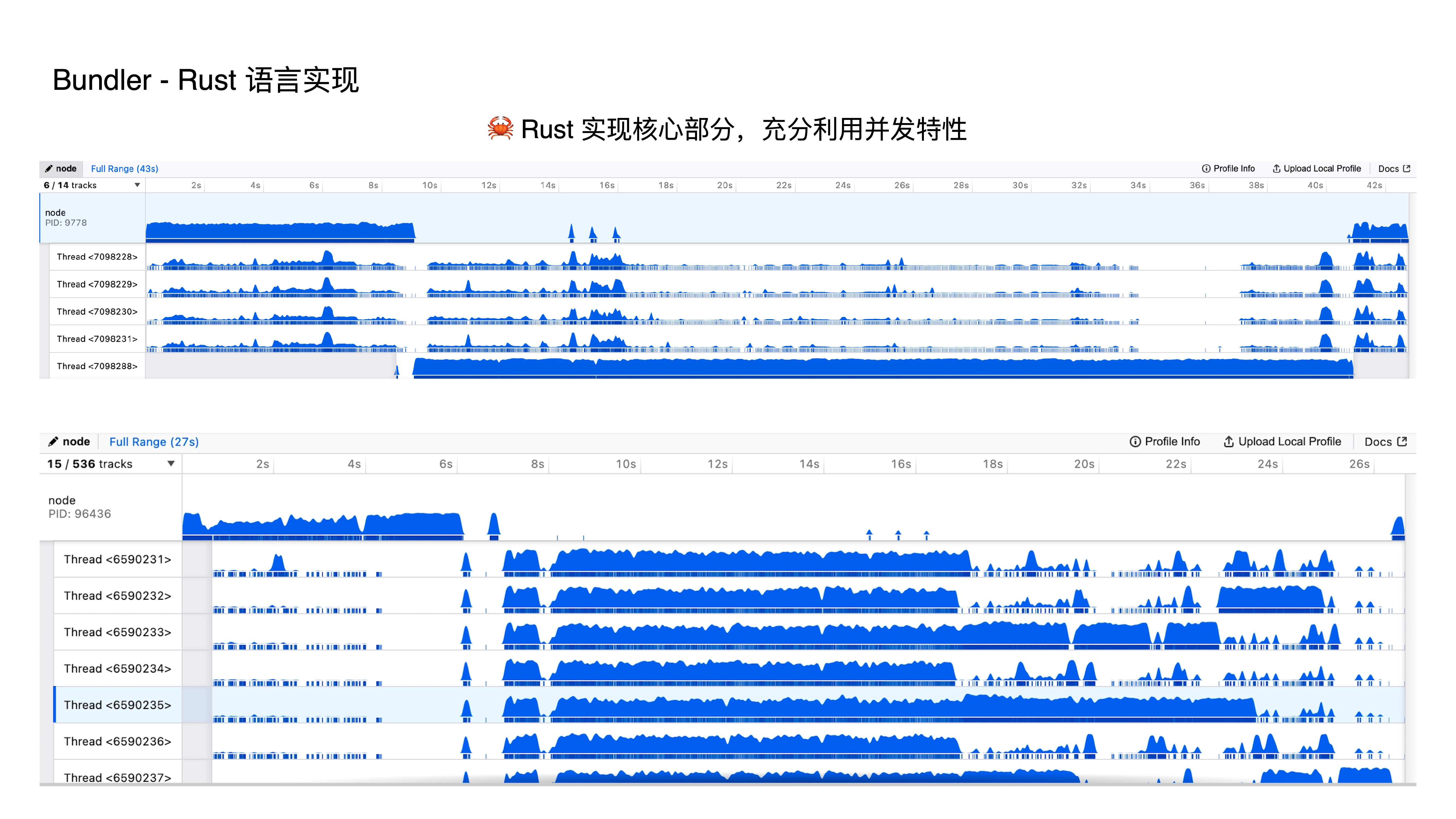
- First, the high-performance feature — implemented in Rust. Since JS is single-threaded, and while there are ways to achieve concurrency in JS, they all feel like dancing in chains. In Rust, we can natively support concurrency, so we leverage parallel execution of build tasks, which dramatically improves build performance.
- These two images compare thread usage between Webpack and Rspack during builds. You can clearly see that Webpack is essentially single-threaded, while Rspack fully leverages multi-core CPUs to squeeze out maximum performance.
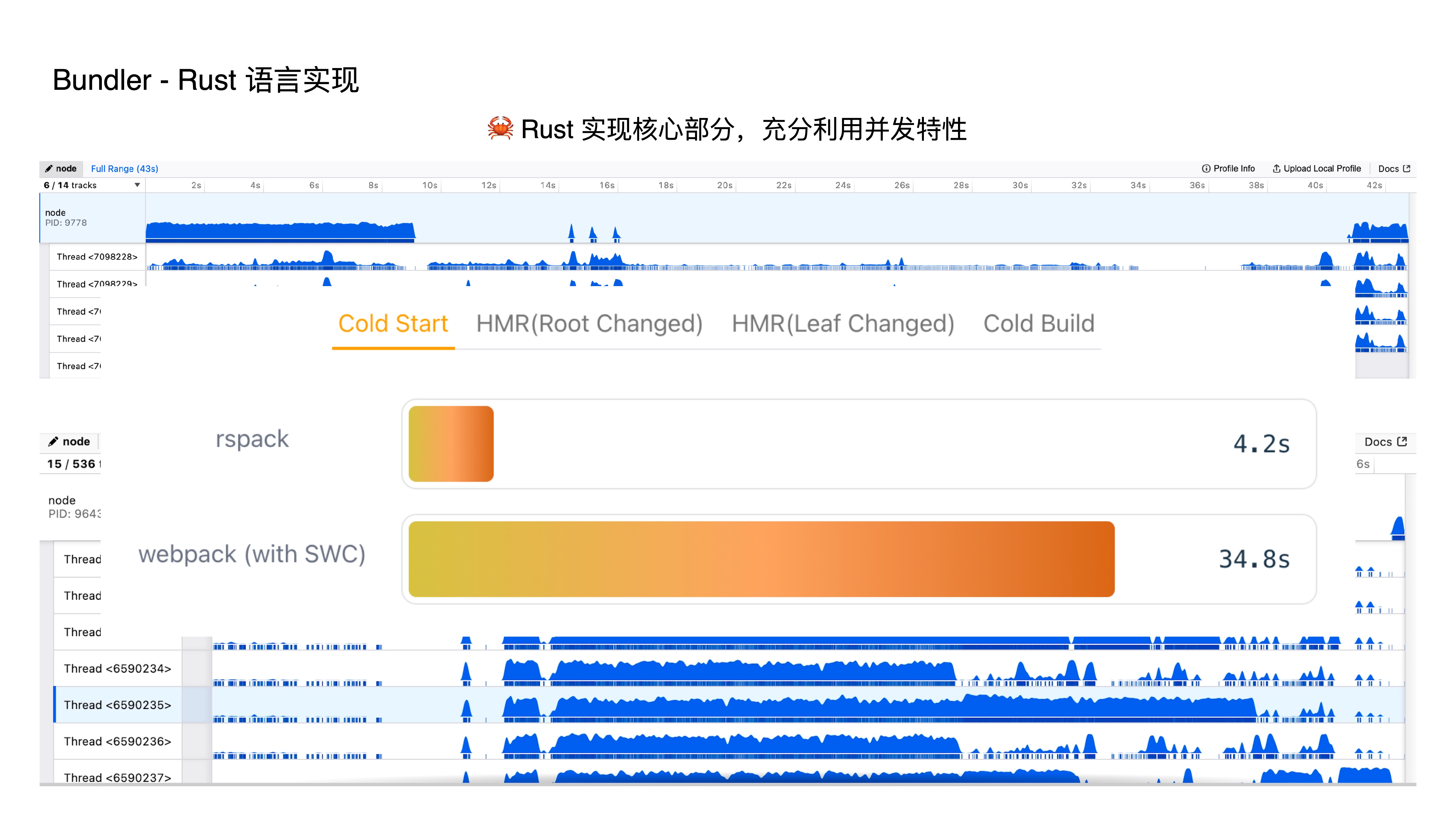
- This is a comparison chart from our official website. For the same project, Rspack takes only 4.2 seconds, while Webpack takes 34.8 seconds.

- Rspack’s second feature is partial compatibility with webpack. The current implementation can be understood as a subset of webpack, containing most commonly used configurations to satisfy daily business development. Why be compatible with the webpack ecosystem?
- First, webpack’s plugin mechanism meets projects’ customization requirements.
- Second, reusing webpack’s rich ecosystem means optimizing giant project development experiences at minimal cost.
- Third, there are a massive number of existing webpack projects — compatibility greatly reduces migration costs.
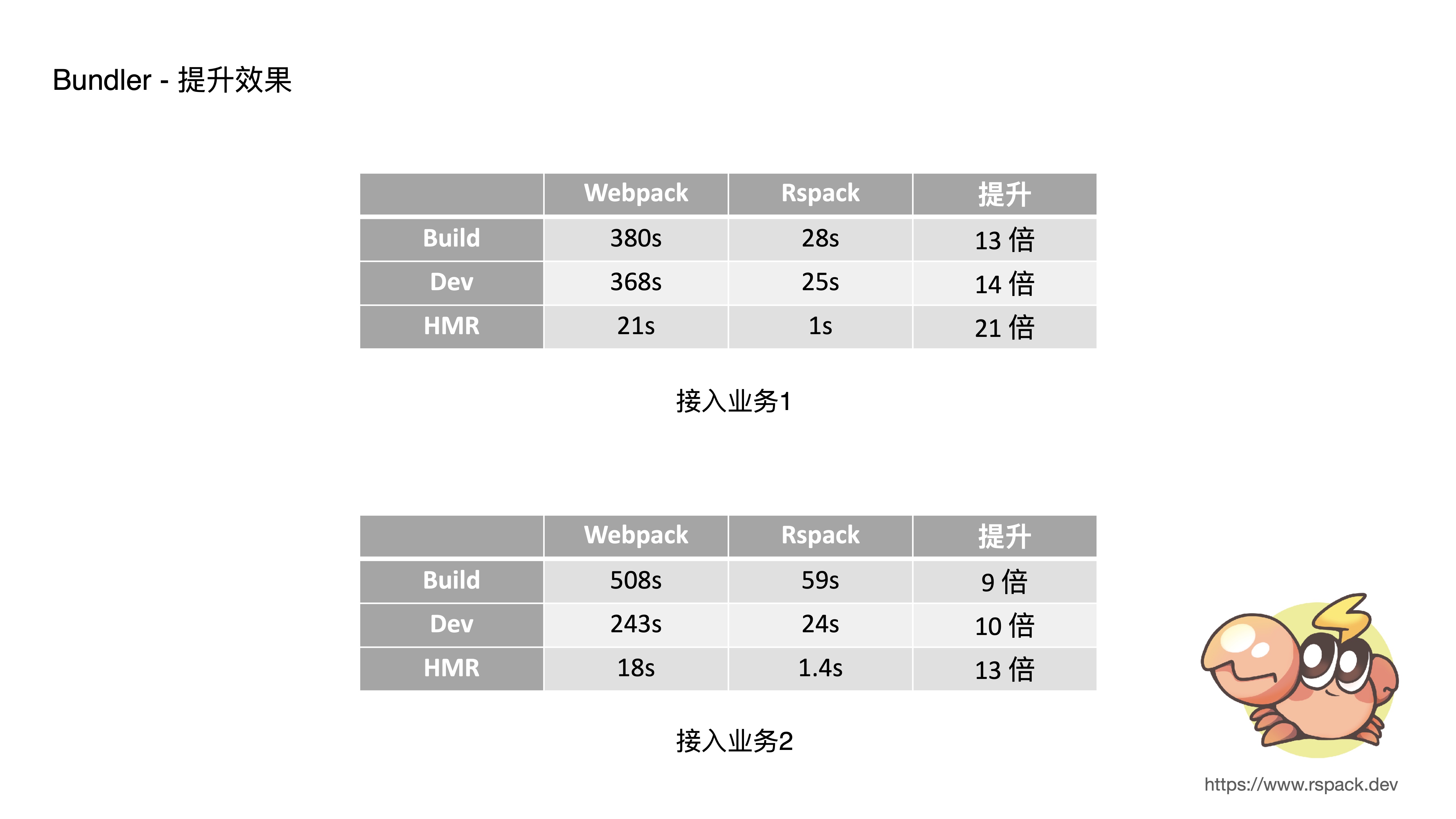
- Here are the results from two typical business applications. Both originally took about 5 minutes for dev startup — with Rspack, it takes only about 20 seconds. HMR originally took about 20 seconds — with Rspack, it takes only about 1 second. The performance improvement is roughly 10x across the board.

- A brief introduction to Build System: it processes the project dependency graph within a Monorepo and schedules build tasks based on that graph.
- Why does Monorepo need a Build System? Because Monorepo isn’t just about putting multiple projects in a single repository — it also needs a Build System to manage multiple projects and build them according to their dependency relationships.
- Common Build System tools include Bazel, NX, Turborepo, Lage, etc.
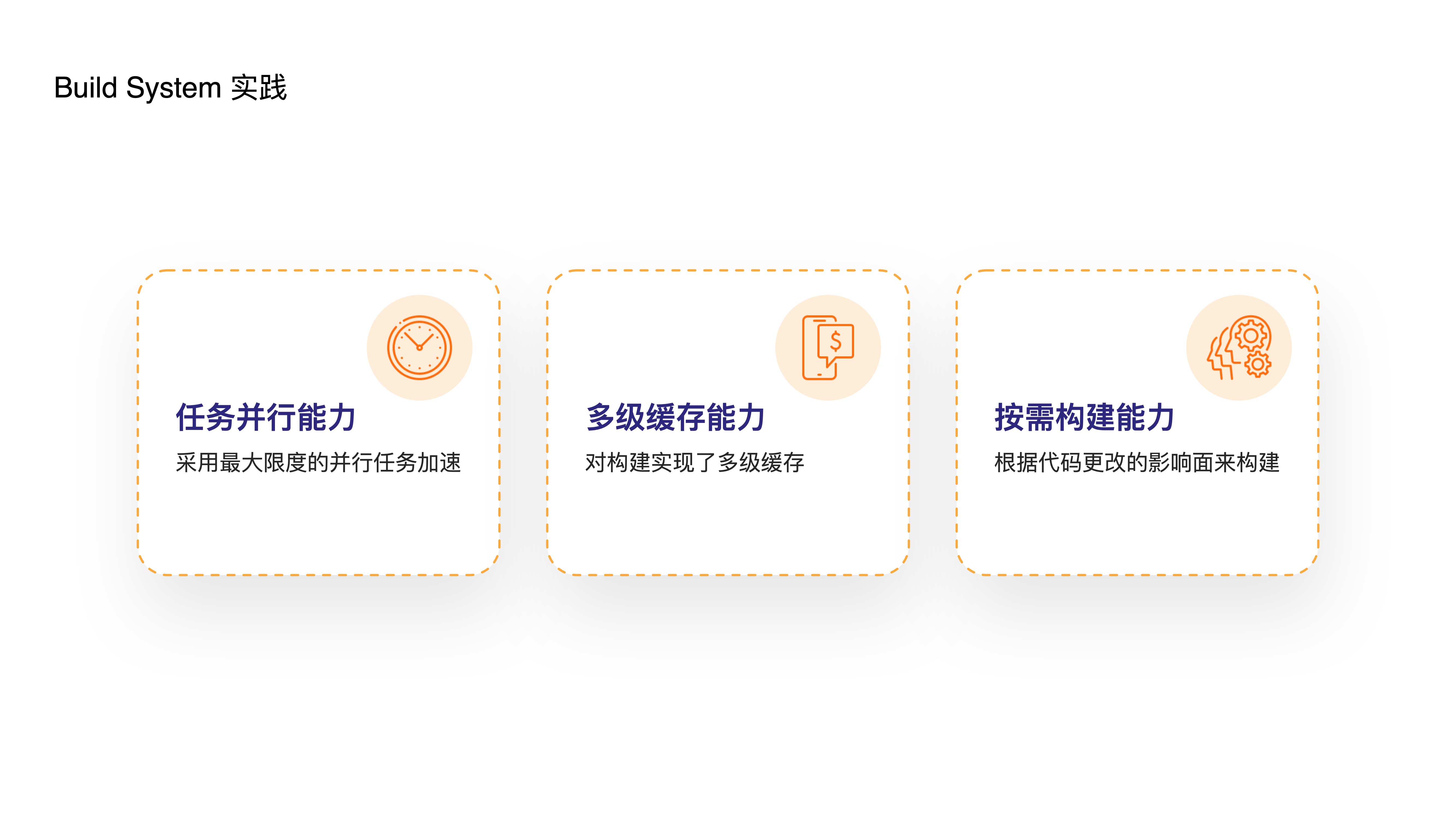
- Let me introduce how we practice Build System in our in-house Monorepo tool:
- Supporting “task parallelism” with maximum parallel task acceleration
- Supporting “multi-level caching” for build tasks
- Supporting “on-demand building” based on the impact scope of code changes
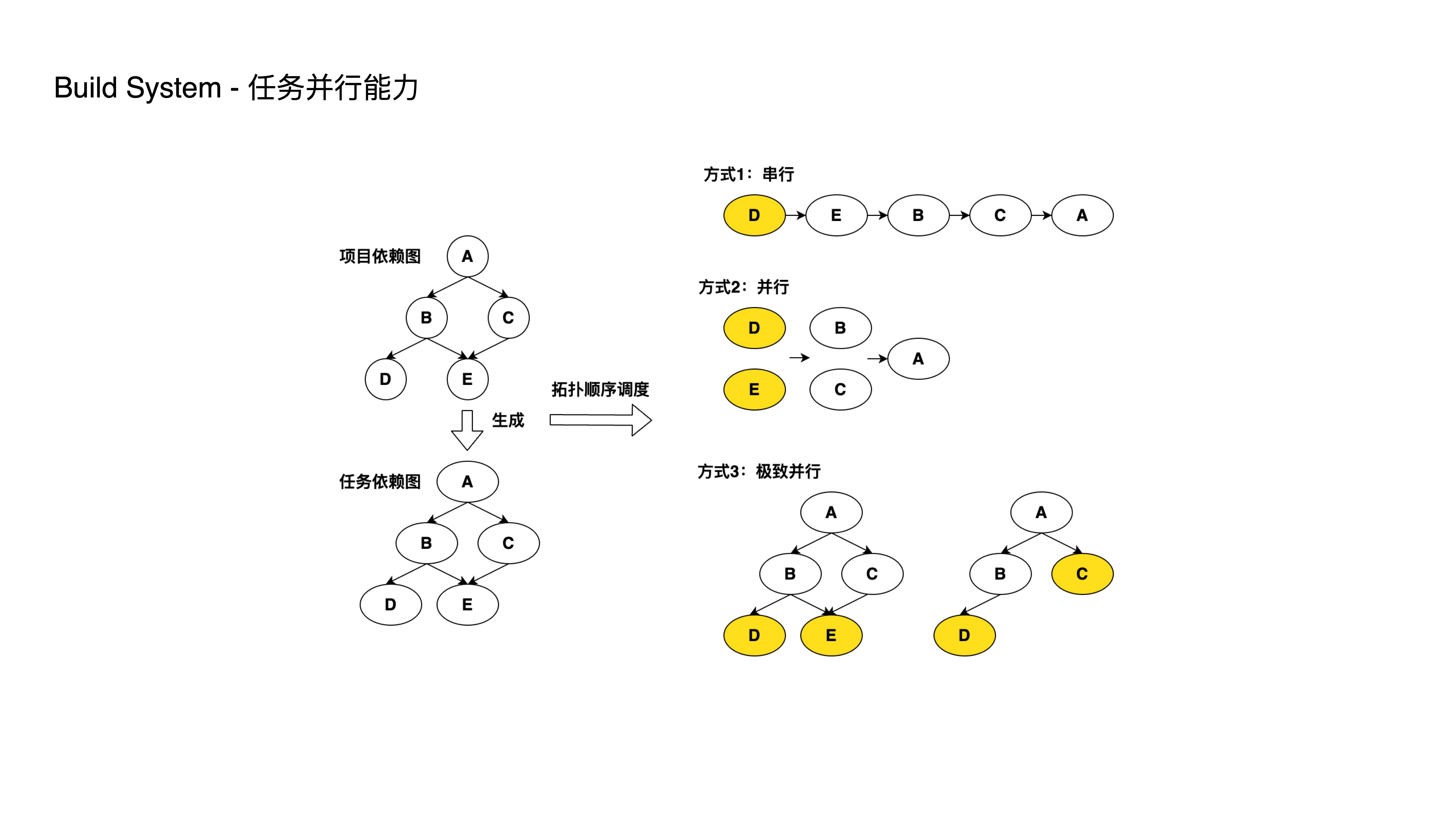
- As shown, we convert sub-project dependency relationships into a task dependency graph. The build order must satisfy the requirement that upper-level projects wait for lower-level project builds to complete.
- OK, let’s look at Approach 1 — serial execution in the order DEBCA. This satisfies the build requirement but has low performance since D and E can be parallelized. So Approach 2 parallelizes DE and BC, reducing 5 steps to 3.
- Then we notice that task C doesn’t depend on task D’s completion, yet in Approach 2, task C has to wait for both D and E to finish.
- This leads to Approach 3: after task E completes, D and C can execute in parallel.
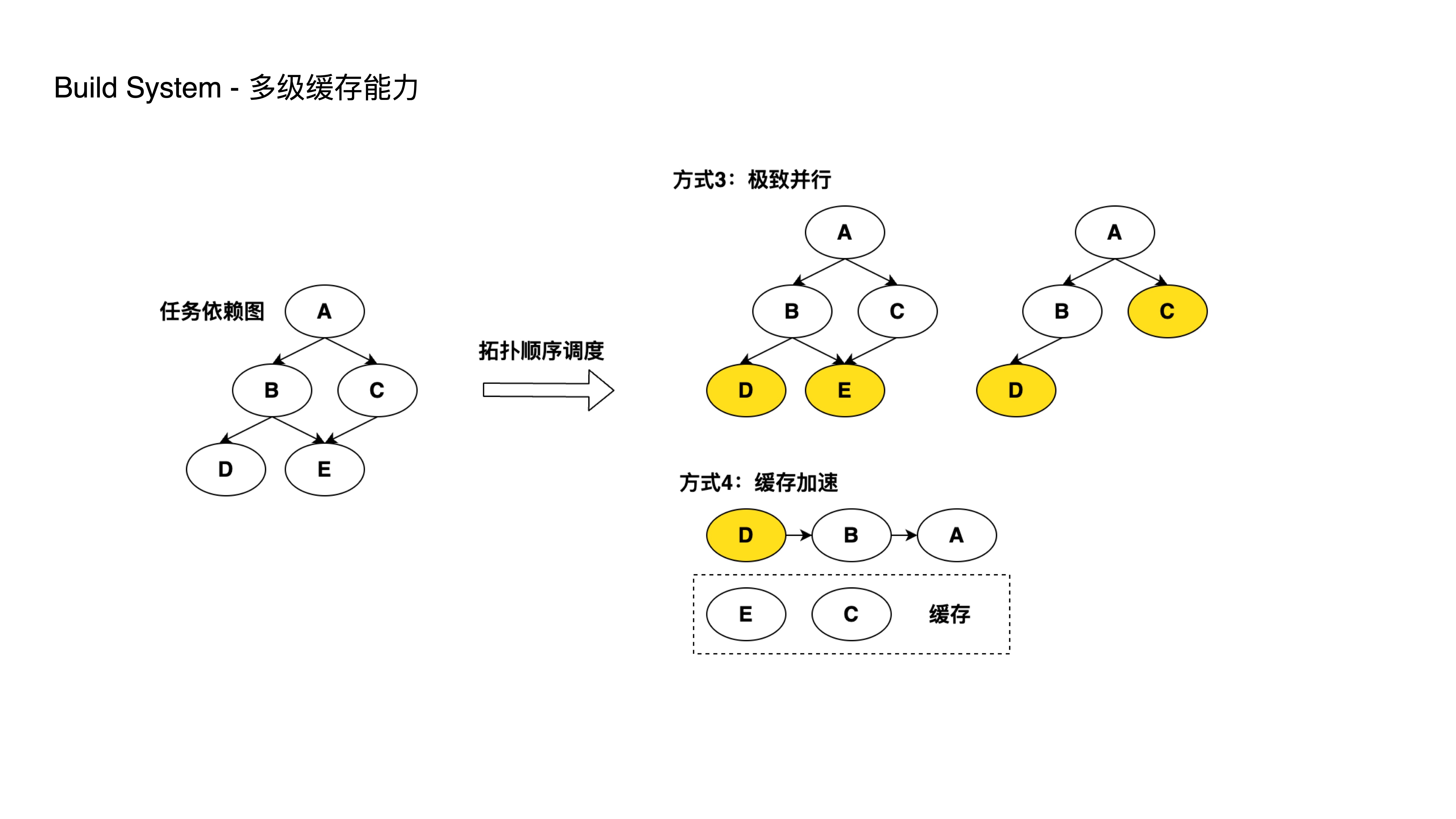
- As monorepo sub-projects scale up, every development or release cycle involves multiple sub-projects. Rebuilding all of them every time significantly slows down build and deployment speeds.
- We provide the ability to cache build artifacts both locally and remotely. When related sub-projects haven’t had code changes, previous build artifacts are reused to reduce build time.
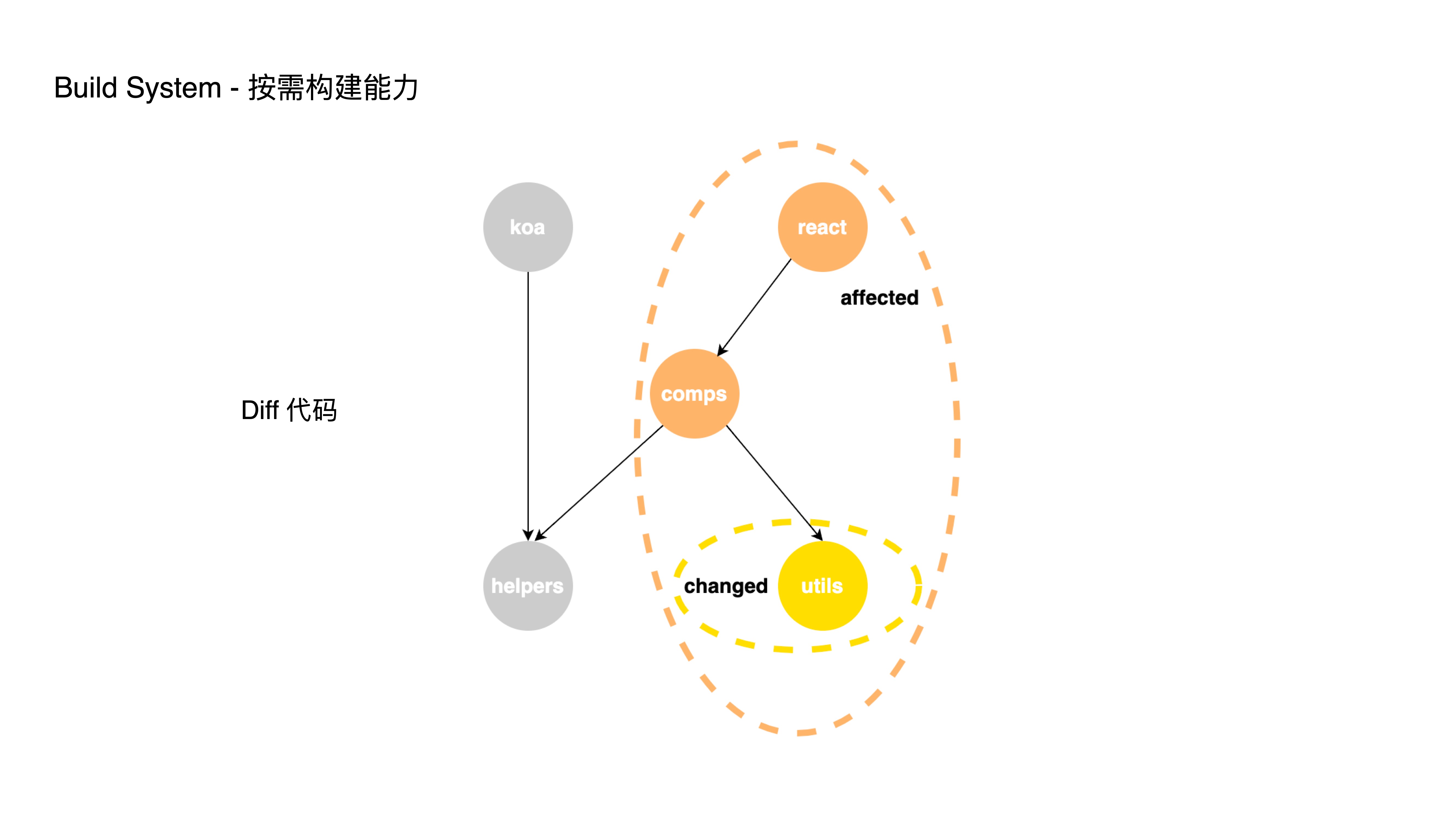
- For on-demand building, we support executing CI processes based on the impact scope. By performing git diff on changed code and analyzing dependencies, we only build the affected projects. Otherwise, every CI run would build all sub-projects in their entirety.
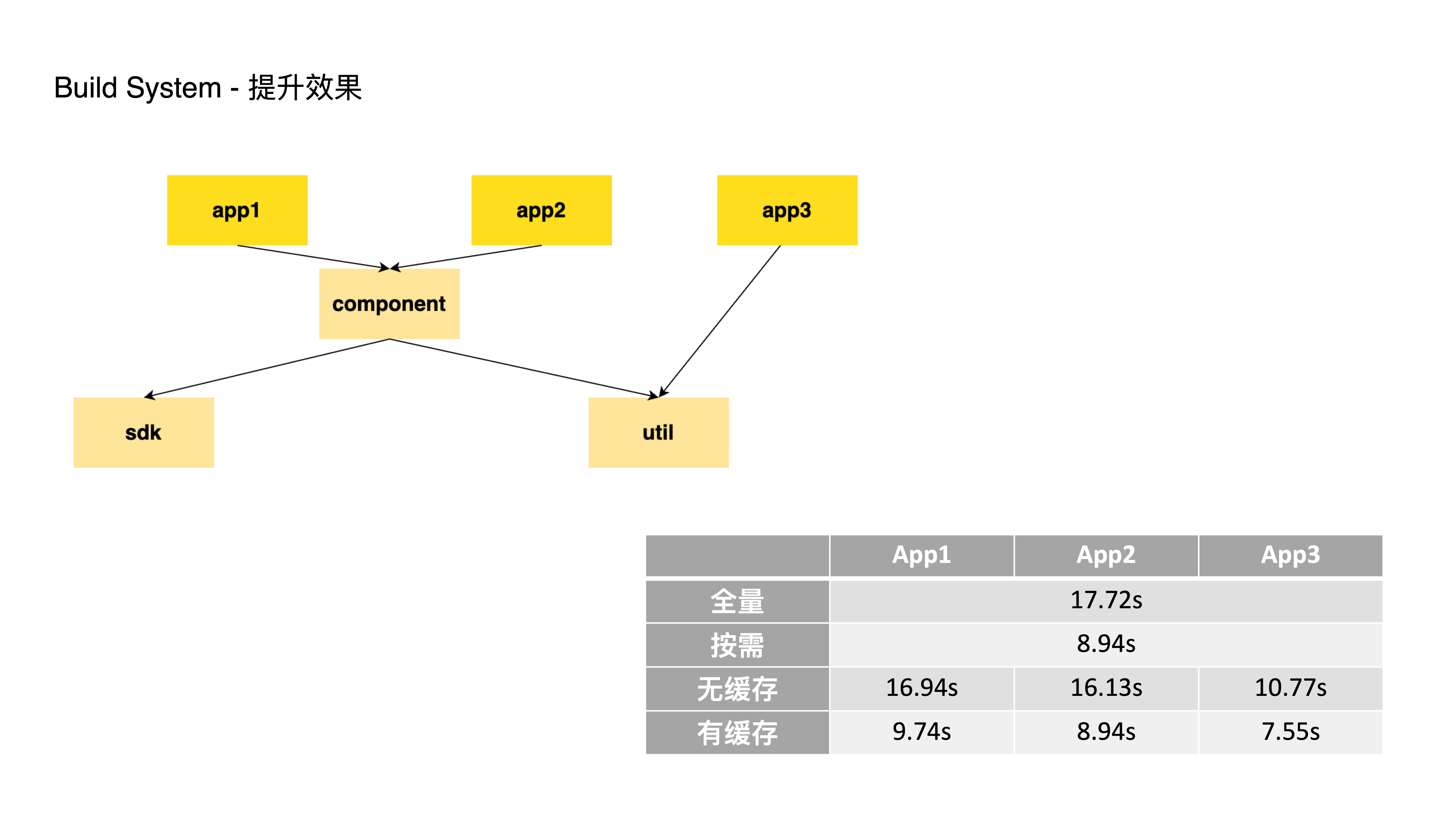
- Here’s a simple Monorepo example with dependency relationships as shown:
- Full build of all projects takes approximately 17.72 seconds
- If only the component module is changed, on-demand building requires building only component, app1, and app2, taking 8.94 seconds — a 50% time saving
- Without caching, building just App1, App2, and App3 takes between 10.77 and 16.94 seconds
- With caching (e.g., component, sdk, and util already built), building App1, App2, and App3 individually takes between 7.55 and 9.74 seconds — approximately 45% time saving

- Through building both the Bundler and Build System, we’ve leveraged Rust’s high performance and remote build caching capabilities to dramatically accelerate build speeds for giant applications. But this isn’t just about development speed — it brings two enormous business benefits:
- Raising the ceiling of monolithic applications: enabling us to develop even larger and more powerful applications
- Accelerating iteration speed: enabling faster and more frequent AB testing and feature releases
- Micro-frontend is essentially a divide-and-conquer solution for frontend applications. ByteDance’s micro-frontend practices have gone through iframe, SPA, and framework phases. We encountered many issues along the way, and to further reduce multi-person collaboration costs, we’re now exploring a new approach.

- Let’s look at how the new micro-frontend approach reduces multi-person collaboration costs:
- First, by lightening the base application burden — decoupling the base application from business logic
- Second, by adopting fine-grained composition — enabling independent development and deployment at a more granular module level
- Finally, by establishing module protocol standards, we’ve built a module center and can even integrate with low-code platforms, leading to higher module reuse rates; and we support module-level canary releases and AB testing capabilities.
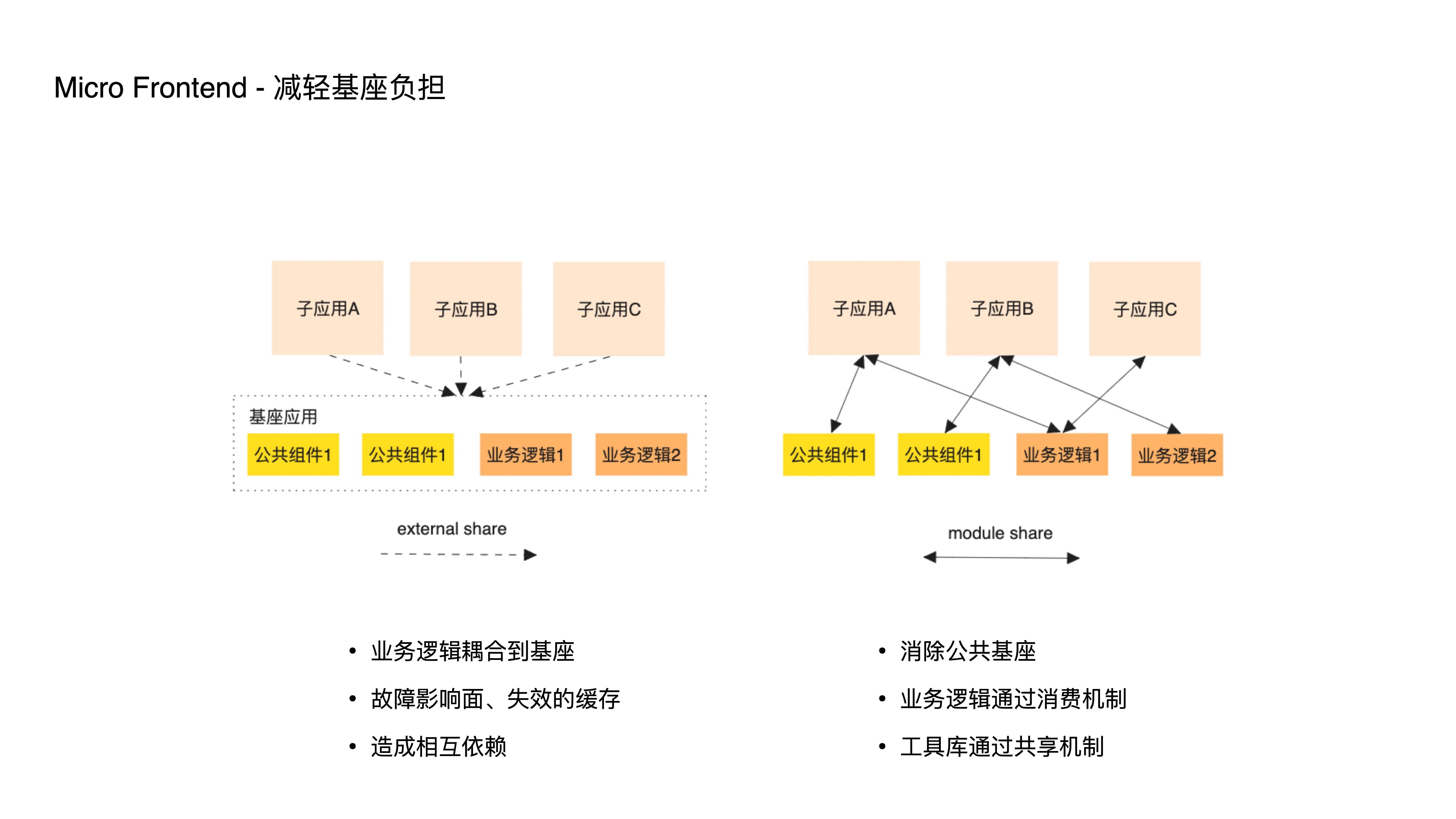
- How does it lighten the base application burden? In traditional micro-frontends, a shared base application carries common logic. This reuse approach, beyond utility libraries, often leads to business logic coupling into the base, causing more frequent changes and releases, larger failure blast radii, and more frequently invalidated caches.
- This pushes sub-applications from independent development and deployment back to some degree of interdependence. Therefore, the new approach eliminates this type of base through two mechanisms: a consumption mechanism and a sharing mechanism. The former is generally used for reusing business logic, and the latter for reusing business-agnostic utility libraries.
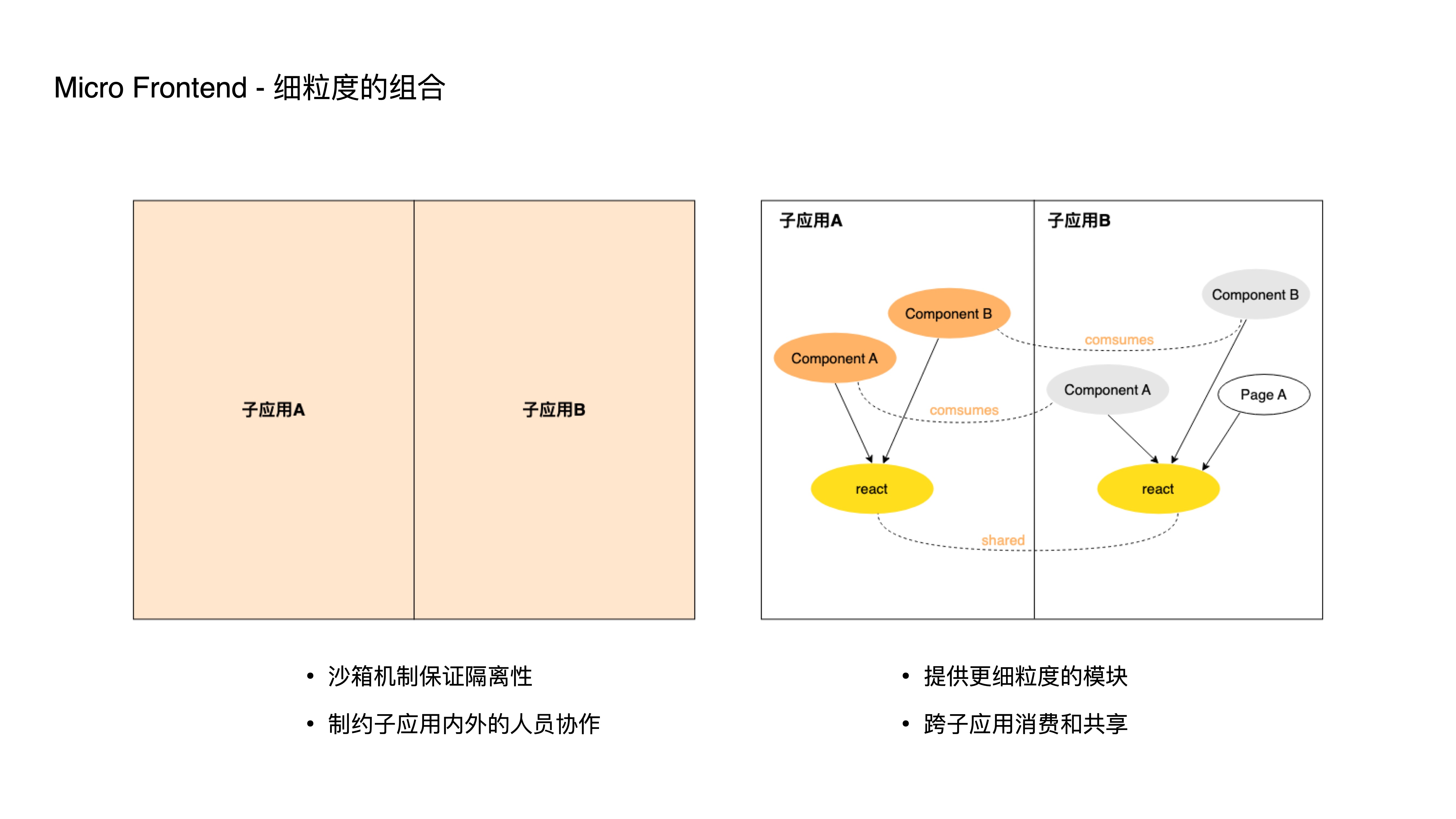
- How does the new approach’s mechanism work?
- In traditional micro-frontend architecture, multiple sub-applications are relatively isolated, typically through a sandbox mechanism to ensure this isolation.
- But as frontend sub-application scale and team size grow, such coarse-grained isolation can constrain collaboration within and across each sub-application.
- Therefore, our new approach provides more fine-grained module consumption and sharing solutions, enabling developers to independently develop, test, and deploy at smaller unit levels.
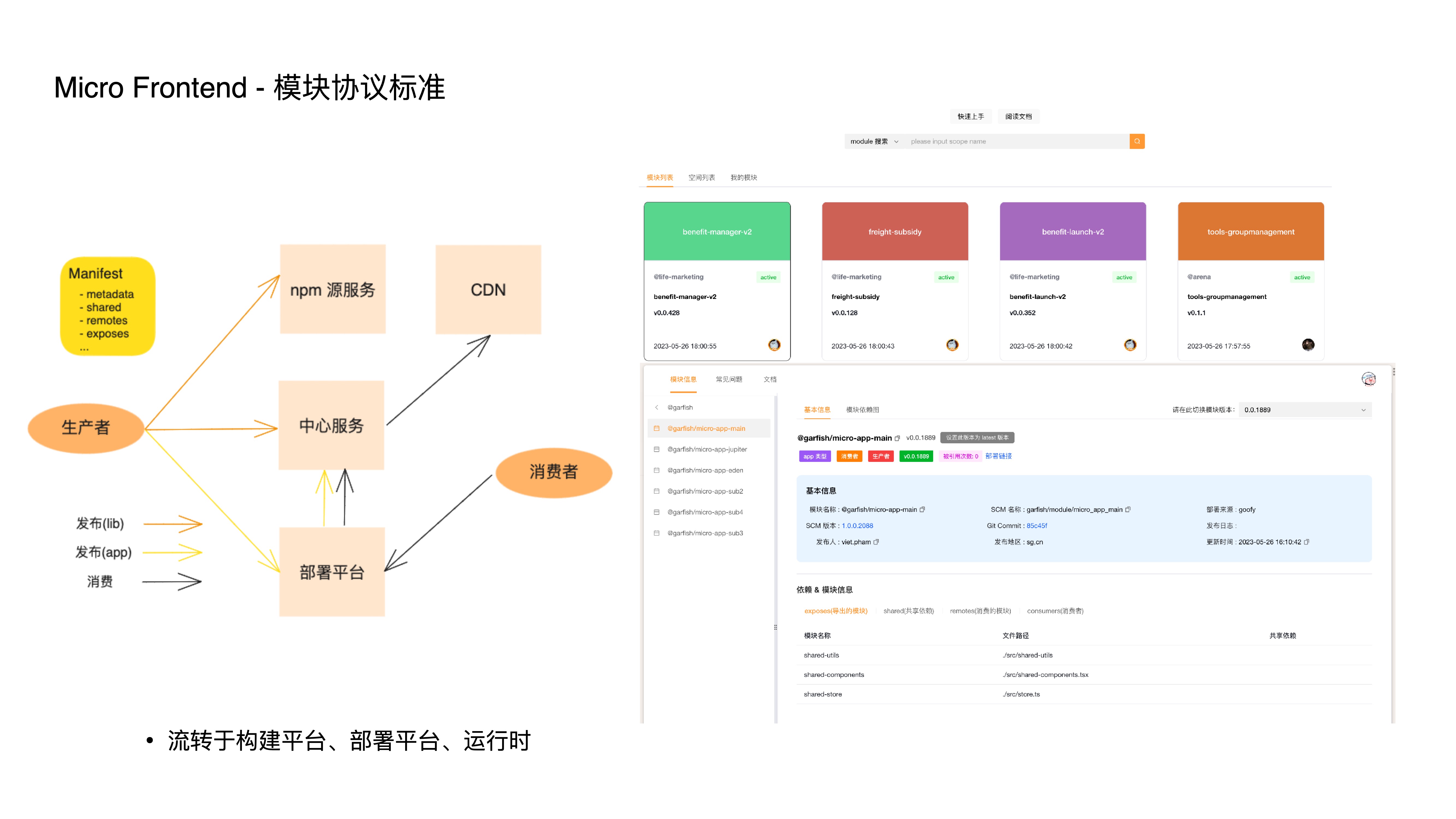
- The module protocol standard defines module metadata. Through this protocol, modules flow between various platforms to achieve specific functions:
- For example, the build platform generates this protocol file based on configuration
- The deployment platform converts metadata into data containing specific CDN addresses, which is directly injected into the HTML for delivery — this step is the prerequisite for module-level canary releases and AB testing
- The application runtime also dynamically loads modules based on this protocol
- With fine-grained composition and module protocol standards, we can conveniently establish an online module center. Whether business-related components or business-agnostic utility libraries, they can be reused at extremely low cost within a team or even across teams.
- Additionally, based on this mechanism, we’ve experimented with low-code platform integration — using low-code platforms to build components that conform to the module protocol standard. Once registered as online modules, this dramatically improves business development efficiency.
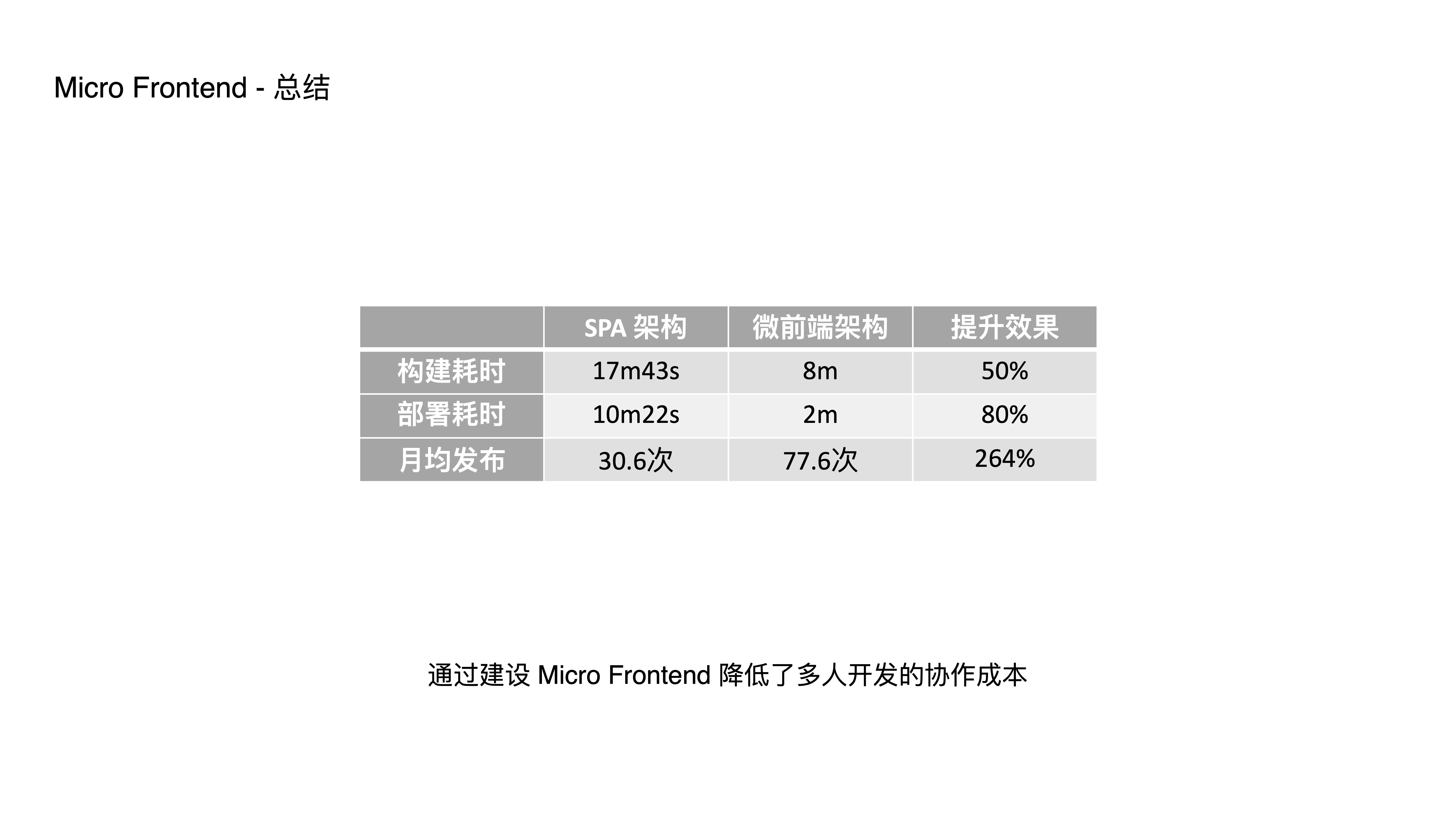
- This is a typical adopting business. After integration, we saw significant improvements in build time, deployment time, and even iteration speed and requirement throughput.

- Next, let’s discuss diagnostics tools. Most tools on the market focus on diagnosing and analyzing build artifacts but can’t perform deeper diagnosis and analysis of the build process, which limits their usefulness.

- How does our in-house diagnostics tool effectively prevent application degradation?
- First, by providing build-process-oriented analysis capabilities. Since we record build process data, we can offer more fine-grained and richer analysis.
- Second, by providing an extensible rule mechanism that allows different vertical and business scenarios to extend their own rules.
- Finally, by integrating with core development workflows to make rules actually take effect.
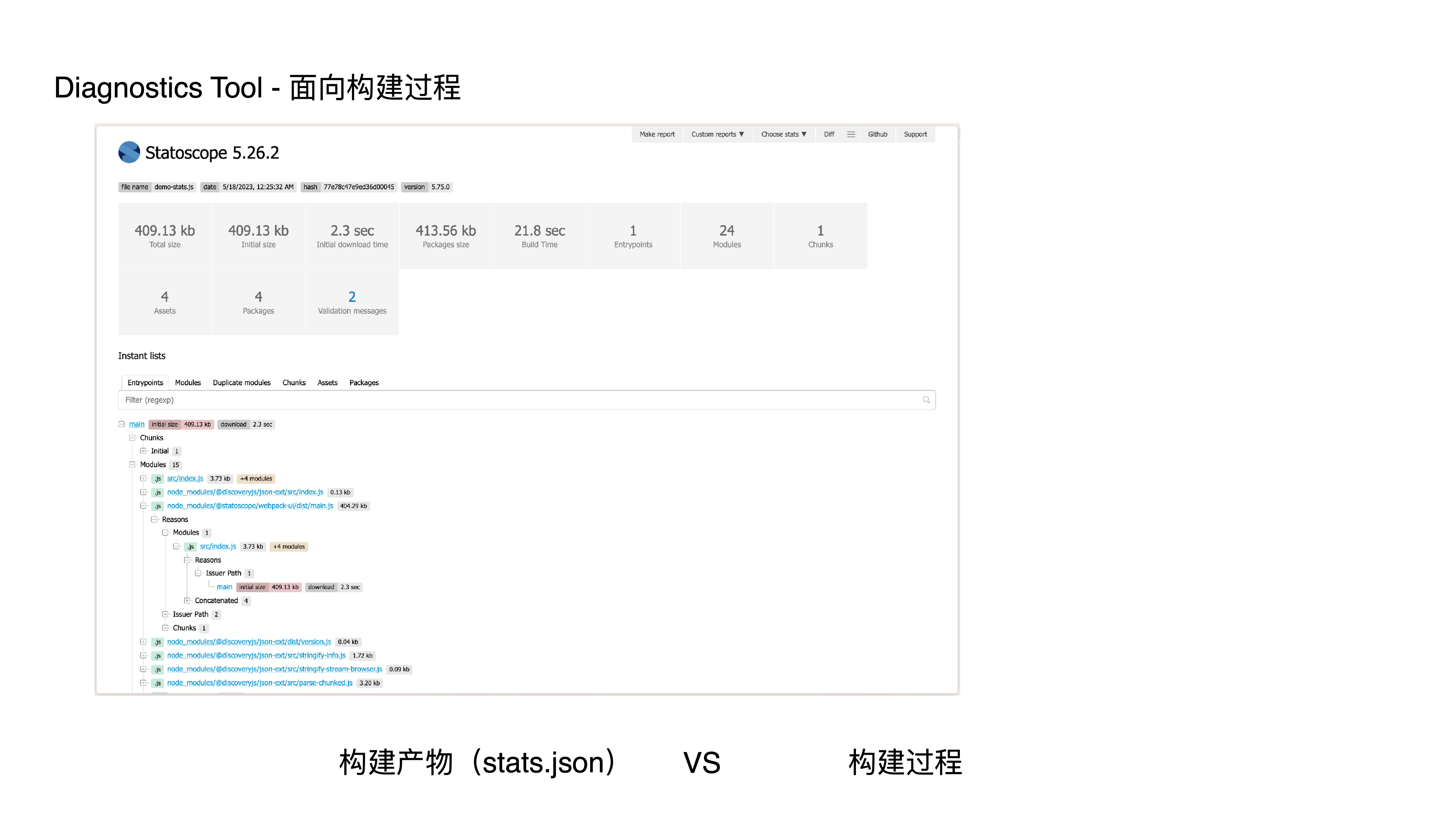
- This is an analysis result page from Statoscope, a typical build-artifact-oriented analysis tool that consumes stats.json to analyze artifacts.
- It doesn’t include analysis and diagnostics for build-process-related aspects like loaders, resolvers, or plugins.
- Our tool can provide the following capabilities:

- Webpack loader timeline analysis
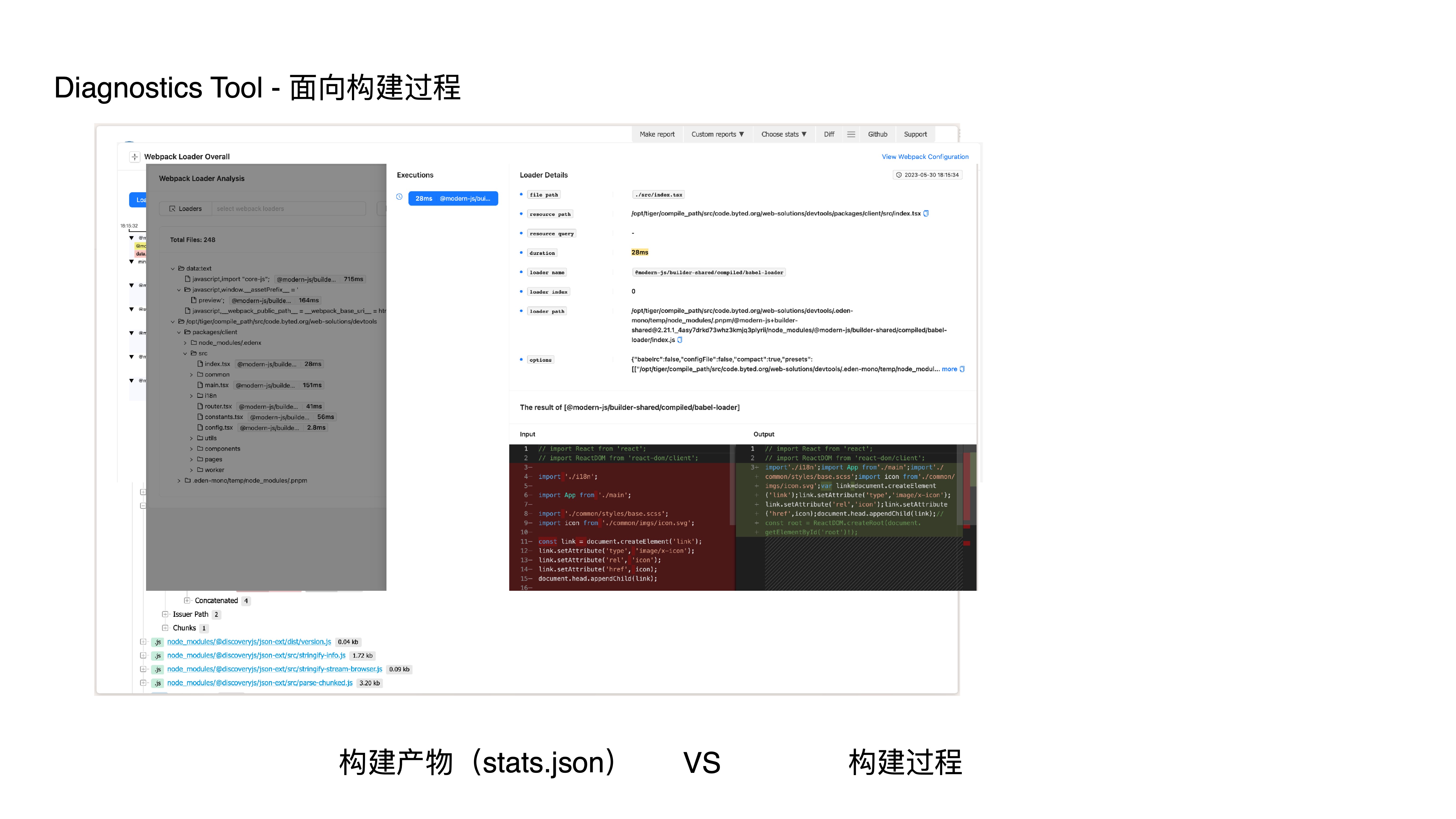
- Webpack loader analysis

- Webpack resolver analysis
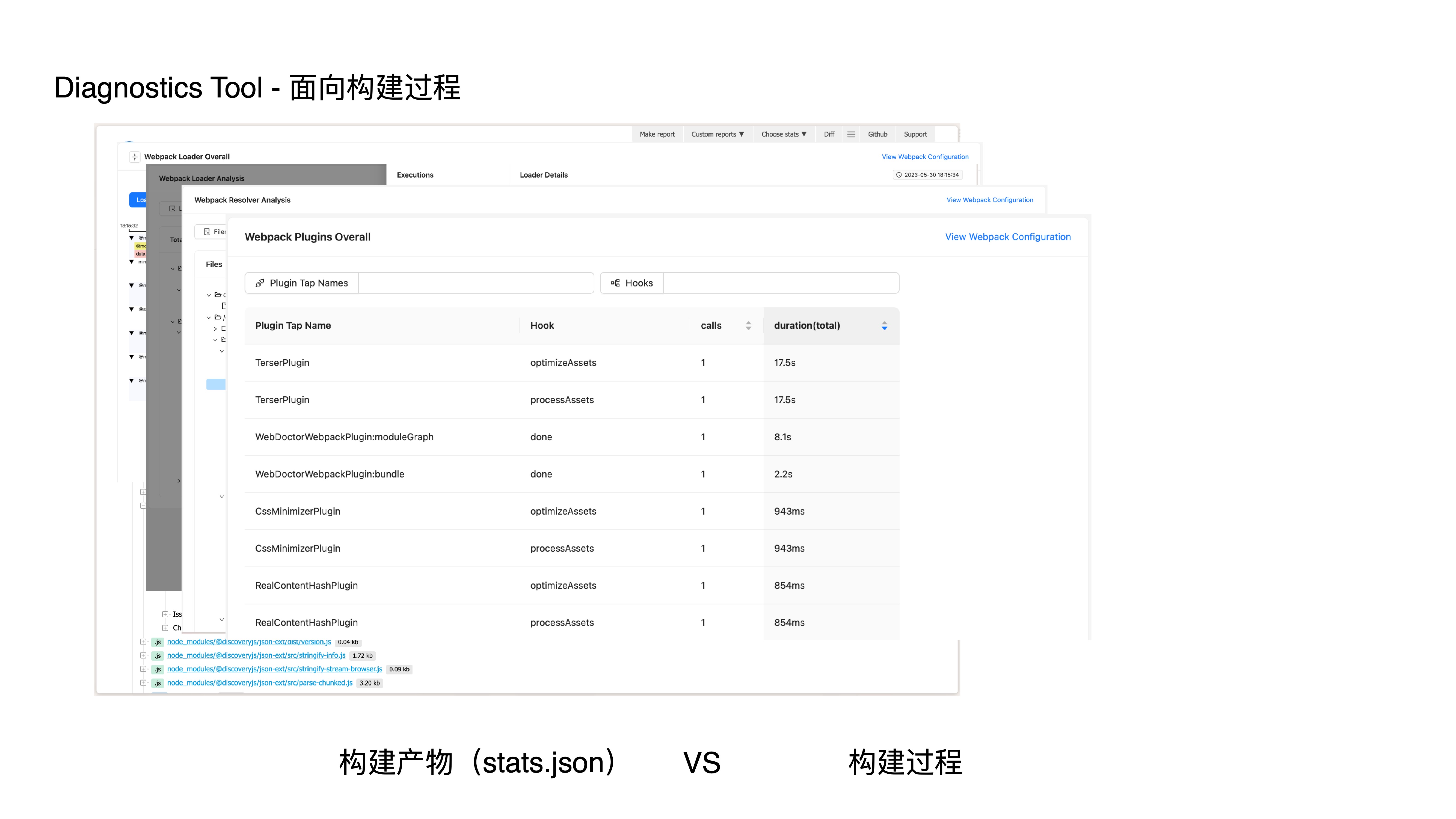
- Webpack plugin analysis
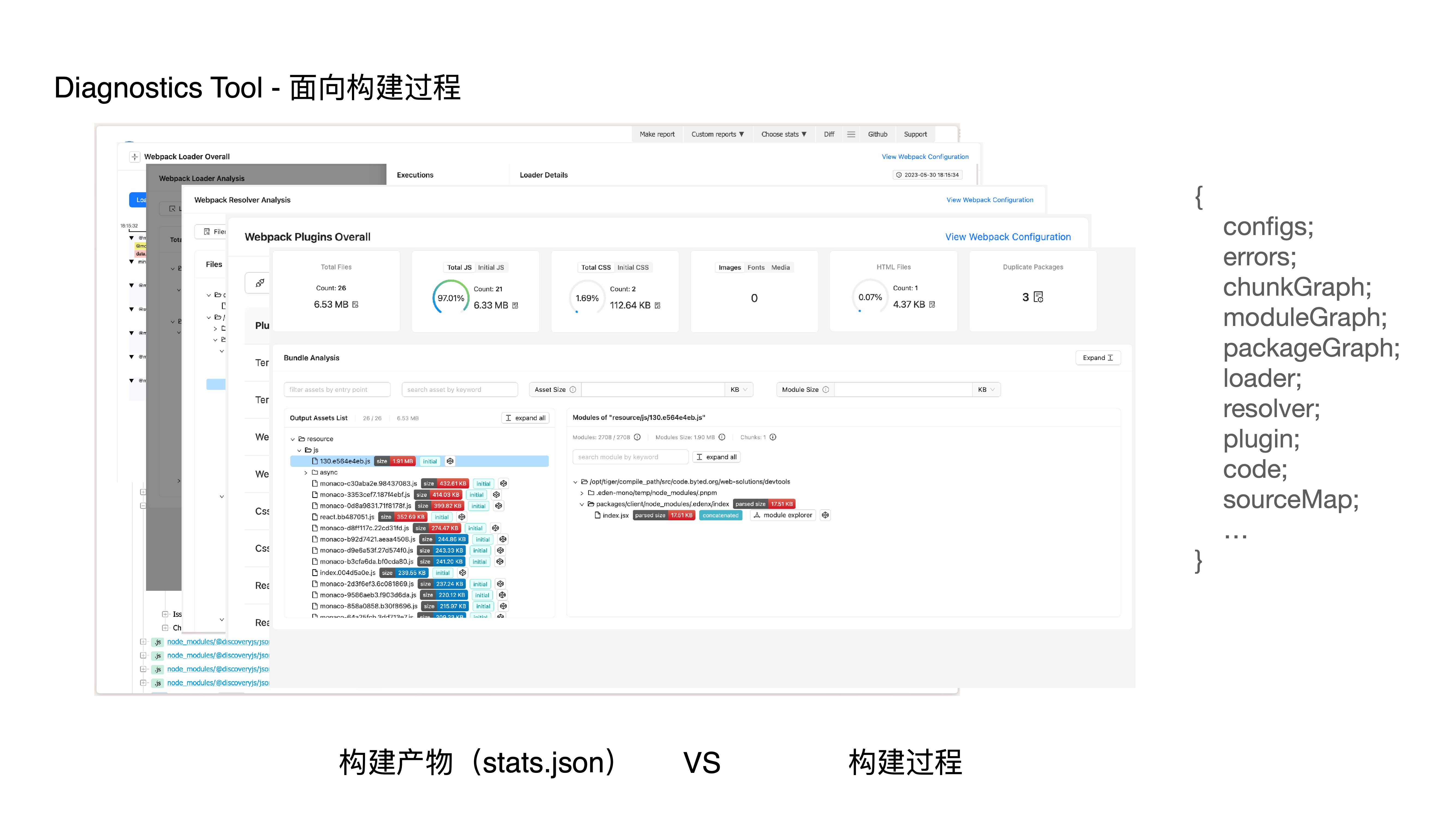
- Bundle deep analysis
- How do we achieve this? We hook into the build process by listening to plugin hooks and intercepting loaders, collecting and generating data structures specifically designed for diagnostics and analysis scenarios — including dependency graphs, module graphs, third-party package graphs, source code, loader, plugin, resolver data, and more. This provides us with more comprehensive build context information for deeper diagnostics and analysis.

- We provide some default diagnostic rules, such as:
- Duplicate Packages check
- Default Import Check for package specification compliance
- Loader Performance Optimization
- Additionally, we provide an extensible diagnostic rule mechanism. We pass our regenerated data structures as context to custom rules, enabling capabilities such as:
- Dependency import method checks
- Specific dependency version checks
- Prohibition of specific statements
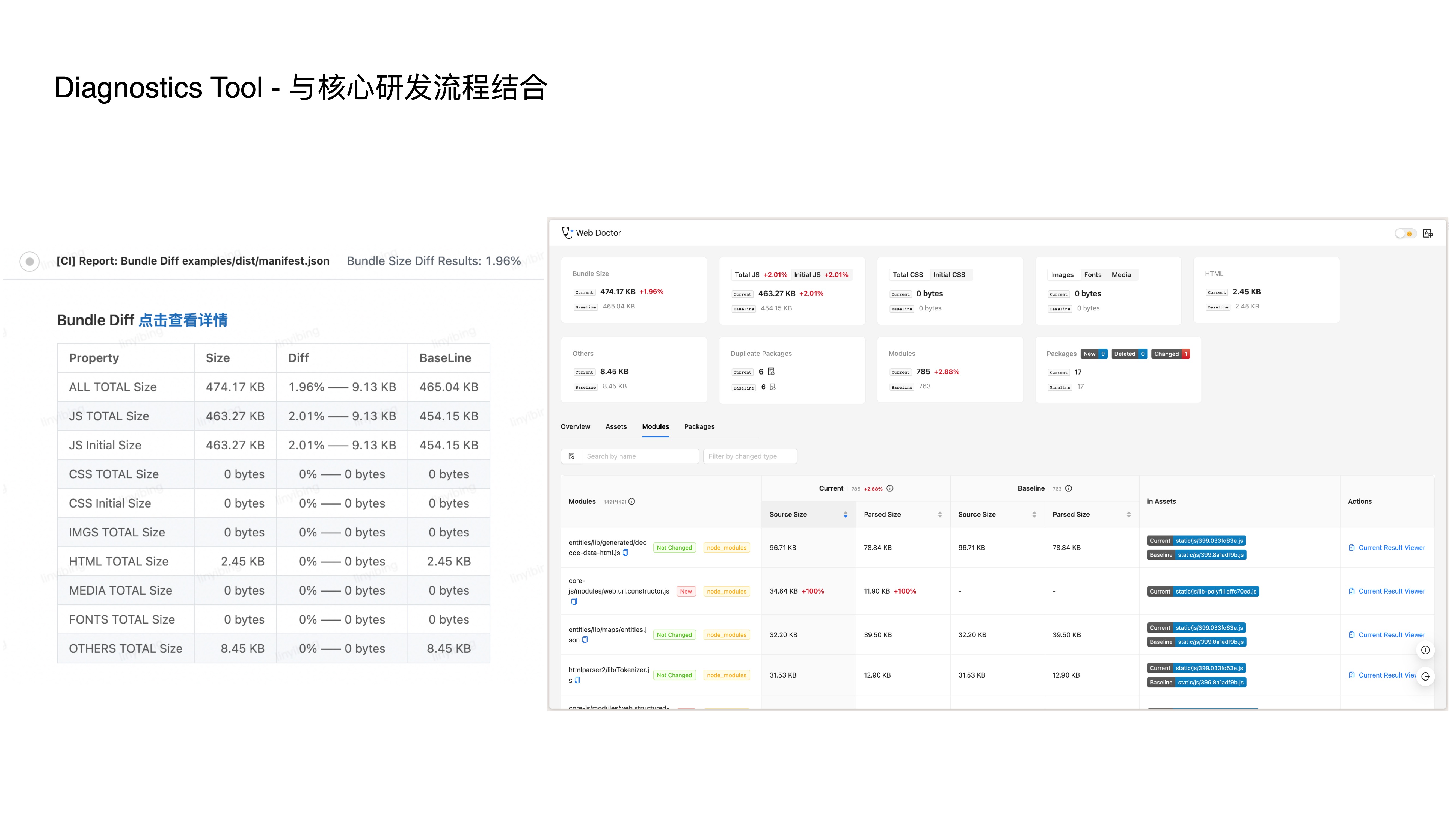
- The above two capabilities alone aren’t enough. We also integrate with core development workflows, supporting branch-based diff interception in CI to make rules truly effective.

- To summarize, here are some typical business benefit metrics.
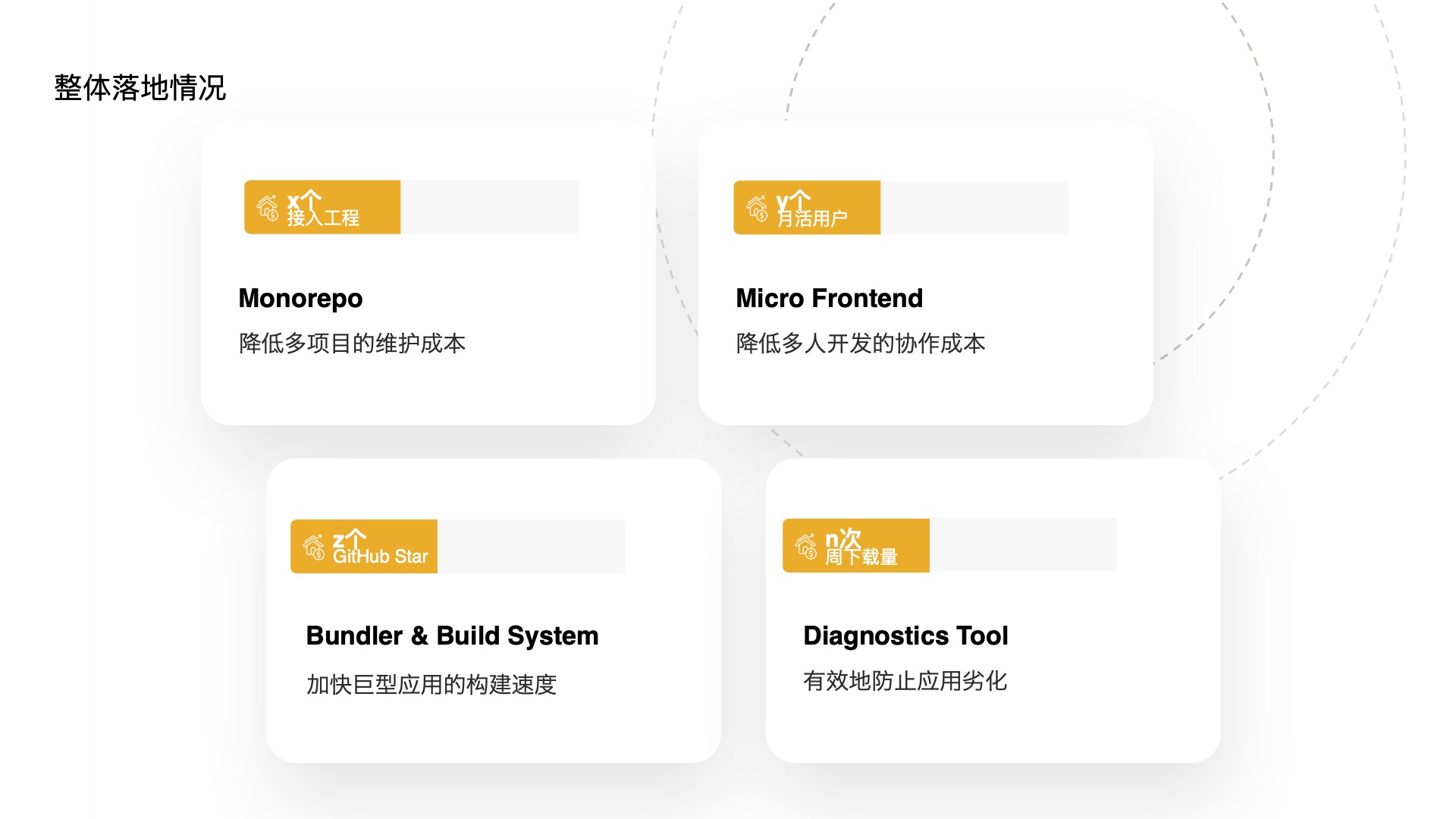
- Here’s the overall adoption status of these tools. The Monorepo tool has been adopted by x projects, the micro-frontend framework has y active users, the Bundler’s open-source tool Rspack has z stars, and the diagnostics tool has n weekly downloads.
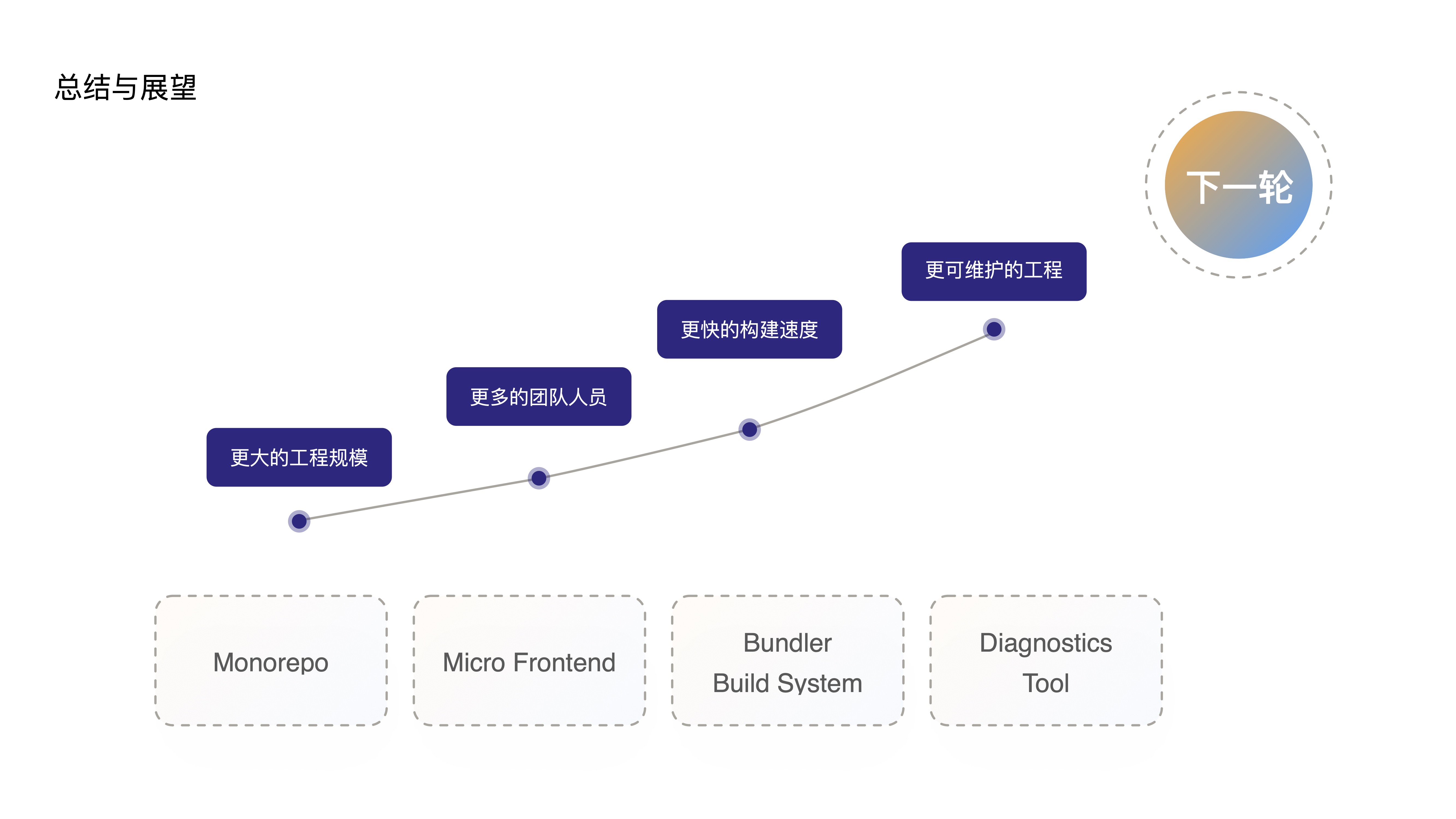
- Let me offer a brief summary and outlook:
- When this series of tool chains supports larger project scales, more team members, faster build speeds, and more maintainable frontend projects,
- I believe the future will inevitably give rise to even more “powerful” frontend applications. As these more powerful applications continue to grow in scale and team size, gradually slowing build speeds and reducing maintainability,
- The future will inevitably demand even more from these tools, driving yet another revolution in the frontend toolchain.

- Thank you, that concludes my talk today.
Slides Attachment
Frontend Engineering Practices at ByteDance
http://quanru.github.io/2023/06/17/Frontend-Engineering-Practices-at-ByteDance

