给 Midscene 加一个新动作,要改多少地方?
这是我衡量一个框架设计好不好的土办法。如果加一个”下拉刷新”手势,得改定位逻辑、改规划提示词、改执行分发,再顺手补一堆 if-else,那这个框架迟早会被自己的动作集合压垮。
Midscene 的答案是:加一处就好。这篇讲它是怎么做到的,以及它没做到的那部分。

给 Midscene 加一个新动作,要改多少地方?
这是我衡量一个框架设计好不好的土办法。如果加一个”下拉刷新”手势,得改定位逻辑、改规划提示词、改执行分发,再顺手补一堆 if-else,那这个框架迟早会被自己的动作集合压垮。
Midscene 的答案是:加一处就好。这篇讲它是怎么做到的,以及它没做到的那部分。
经常有人问我:Midscene 说自己不绑定模型,是不是就是把 base_url 和 model_name 换一下那么简单?
如果模型只是文本进、文本出,那确实差不多,换个 endpoint 的事。
但视觉 UI Agent 要模型做的事不太一样:它要模型看着一张截图,告诉我们某个元素在画面的什么位置。麻烦就出在这里——每个模型家族报告”位置”的方式都不一样。所以”不绑定模型”对我们来说,从来不是换个 API 那么轻松,而是要把这些不一样的地方,在框架内部悄悄吃掉,让你写的那句 ai('点击登录') 一个字都不用改。

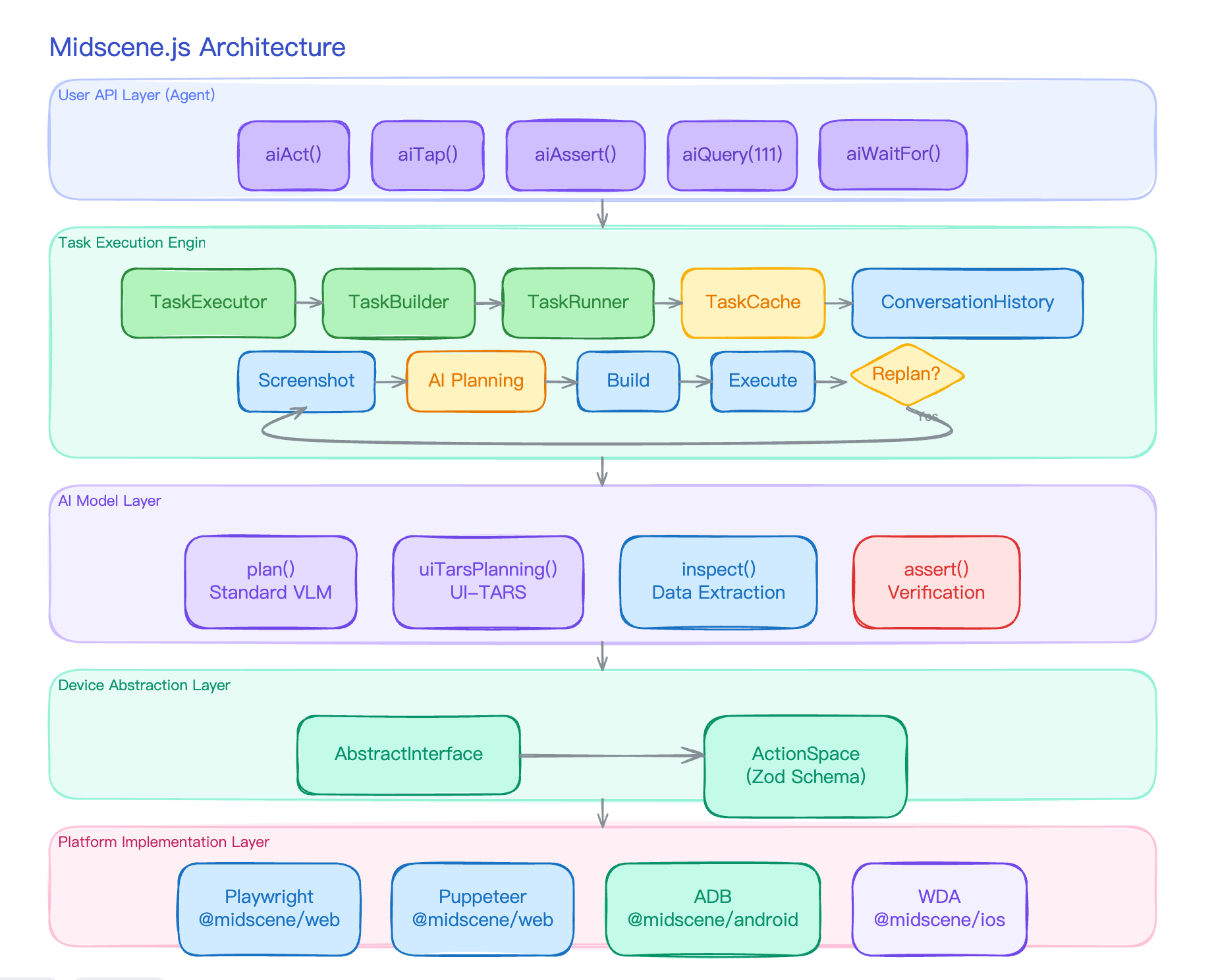
Midscene 为什么要把 Locate 与 Action 拆成两步?
上一篇《Midscene 的一次 aiAct 里到底发生了什么?》讲了 aiAct 内部的规划-执行循环,但里面有一站刻意没展开——**”找元素”**。
这一站其实是 Midscene 里最有技术辨识度的部分。绝大多数视觉 Agent 在这一步要么直接信任 AI 给的坐标,要么再发一次 AI 请求精确定位。Midscene 走了一条不太一样的路:把定位拆出来单独做,并且按”成本从低到高”分四级 Fallback 尝试。
这篇专门讲这件事。
上一篇《为什么 Midscene 的 UI Agent 非得看见屏幕?》讲了 Midscene 为什么把”看截图”放在 UI 操作的最前面。但讲完那个判断之后,我经常被同事问下一个问题:
“那
aiAct内部到底跑了什么?我写一行agent.aiAct('登录后下单'),代码里发生了什么?是一次模型调用吗?”
不是一次。是一个带反馈的循环。
这篇想把这个循环拆开讲一遍:截图怎么拿、AI 返回的是什么、循环什么时候停、多轮之间怎么传上下文。
为什么 Midscene 的 UI Agent 非得看见屏幕?
做 Midscene 的过程中,我经常遇到一个问题:为什么 UI Agent 一定要看截图?为什么不能继续沿用 DOM、selector、XPath、accessibility tree 这些传统自动化里已经很成熟的东西?
这个问题非常合理。过去十几年,UI 自动化基本就是沿着“结构化界面信息”这条路发展起来的。但如果我们要做的不是一个更聪明的 Web 测试框架,而是一个能操作 Web、移动端、桌面端、Canvas、自定义设备的 UI Agent,那么默认信息来源就得换一下:先看见屏幕,再决定怎么操作。
