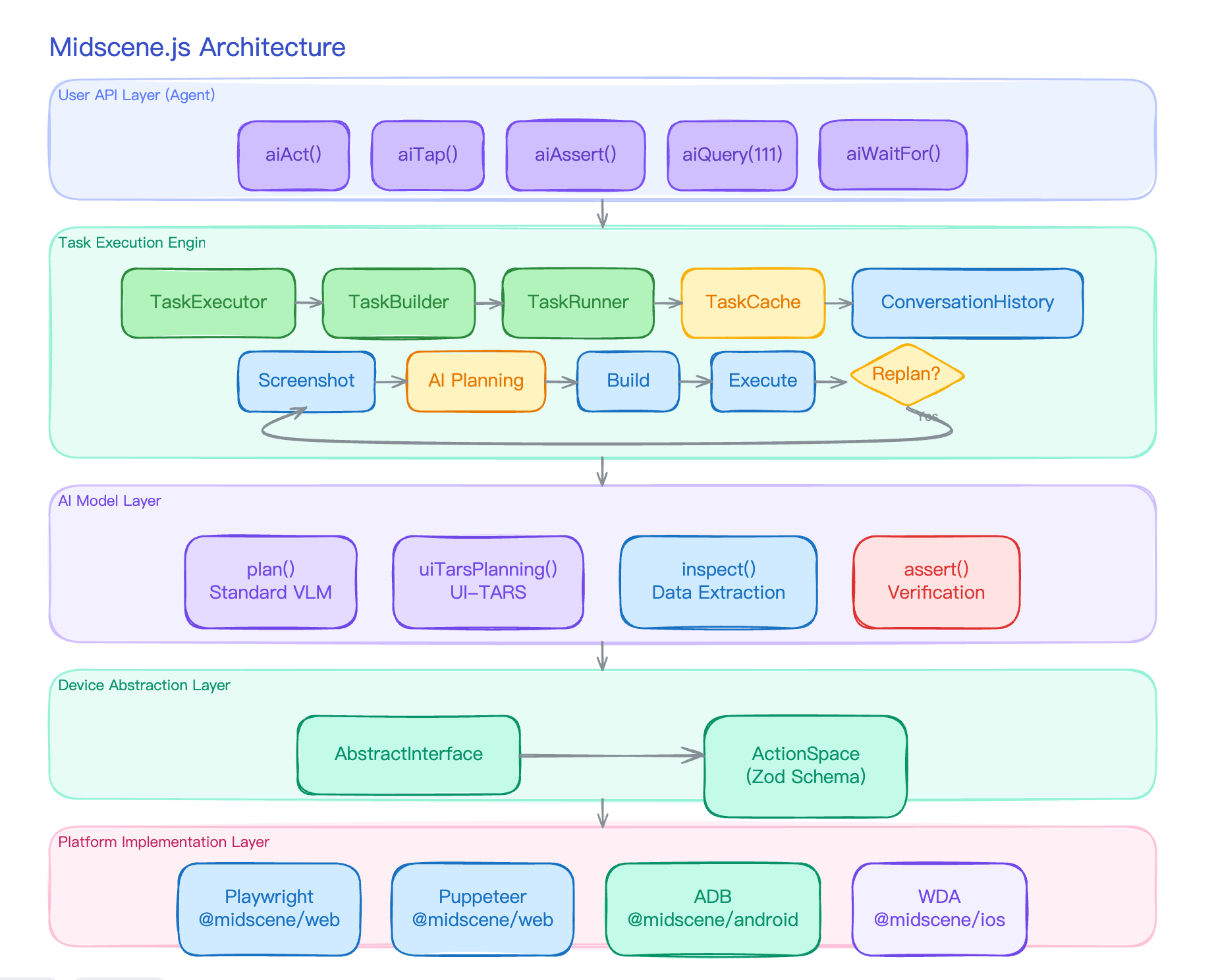
把 Vibecoding 的债变成 Harness(00):我准备用一个真实仓库公开搭一套 harness
如果你也在用 AI 写真实产品代码,应该会熟悉这种感觉:一个功能很快做出来了,但过几天改另一个地方,前面的东西又悄悄坏了。
每次发布前都需要 human in the loop——人肉判断该跑哪个测试、看哪段日志、哪些失败能忽略、哪些失败必须修。心里完全没底。
我现在要做 harness,不是因为工程洁癖,而是这些痛点已经反复出现太多次。所以我决定公开一组 Build in Public,主题就是:在一个真实 monorepo 里搭 harness。